[ 목적 ]
저번에 블로그에 작성한 조인에 대해서 좀 더 깊게 이해한다.
NL, 해시, 소트, 서브쿼리 조인에 대해 적재 적소에 맞게 사용할 수 있다.
[ SQL 튜닝이란? ]
데이터를 읽는 방식에는 2가지가 있다. 논리적 I/O와 물리적 I/O 2가지가 있다.
논리적 I/O는 메인 메모리에 있는 데이터를 읽어오는 것(전기적 신호)이고, 물리적 I/O는 디스크에서 데이터를 읽어오는 것(HDD의 경우 ARM을 움직이며 데이터를 찾아 읽어오는 것)이다.
논리적 I/O는 물리적 I/O보다 10000배 가량 빠르다.
논리적 I/O는 물리적 I/O보다 상대적으로 걸리는 시간이 일정한 편이다. 예를 들면, 물리적 I/O는 디스크의 경합이 심하거나, 장치의 성능이 떨어질 경우 등 다양한 변수가 존재하여 항상 시간이 다르다.
시퀀셜 액세스, 랜덤 액세스 2가지가 존재하는데 이를 적재 적소에 잘 사용해서 빠르게 데이터를 읽고 쓴느 것이 SQL 튜닝이라고 생각한다.
시퀀셜 I/O는 물리적 I/O에 해당하고, 랜덤 액세스는 논리적 I/O에 해당한다. 논리적 I/O는 버퍼 캐시에 있는 데이터 페이지를 가져오는 것을 의미한다.
그럼 여기서 버퍼 캐시에 데이터가 존재하는지 어떻게 판단할 수 있을지 궁금할 수 있다. 아래 접은 글을 통해 확인하자
데이터베이스 컨텍스트에서 캐시 유효성 검사는 데이터베이스 캐시 (버퍼 풀과 같은)에 캐시 된 데이터가 여전히 유효하고 기본 데이터베이스와 일치하는지 확인하는 데 사용되는 메커니즘이다. 이러한 검사는 데이터 무결성을 보장하고 캐시된 데이터의 정확성을 유지하는 데 도움이 된다.
1. 타임스탬프: 캐시의 각 데이터 항목 또는 페이지에는 마지막 수정 시간을 나타내는 관련 타임스탬프가 있을 수 있습니다. DBMS는 캐싱된 데이터에 접근할 때, 캐싱된 데이터의 타임스탬프와 데이터베이스 내의 대응하는 데이터의 타임스탬프를 비교한다. 데이터베이스의 타임스탬프가 더 최근인 경우 캐시된 데이터가 오래되어 새로 고쳐야 한다.
2. 트랜잭션 ID 또는 SCN(시스템 변경 번호): DBMS는 트랜잭션 ID 또는 SCN 값을 추적하여 트랜잭션 순서를 결정합니다. 트랜잭션이 데이터를 수정하면 연관된 트랜잭션 ID 또는 SCN이 업데이트됩니다. 캐시 유효성 검사부는 캐싱된 데이터의 트랜잭션 ID 또는 SCN을 데이터베이스에 저장된 해당 데이터의 트랜잭션 ID 또는 SCN과 비교한다. 데이터베이스의 트랜잭션 ID 또는 SCN이 클 경우 캐시된 데이터가 오래되었음을 나타냅니다.
3. 종속성 추적 : 일부 DBMS 시스템은 종속성 추적 메커니즘을 사용하여 데이터 항목 간의 관계 및 종속성을 식별한다. 데이터 항목이 수정되면 종속성이 기록되고 캐시 유효성 검사는 캐시된 데이터의 종속성을 검사하고 종속 데이터가 수정되었는지 확인한다. 종속성이 무효화된 것으로 확인되면 캐시된 데이터는 유효하지 않은 것으로 간주한다.
4. 일관성 검사 : DBMS는 캐시된 데이터에 대해 주기적으로 일관성 검사를 수행하여 무결성을 보장함
[ NL 조인 ( Nested Loop Join ) - 반복 ]
조인의 기본은 NL 조인이다. NL 조인은 인덱스를 이용한 조인이기 때문에 인덱스의 원리를 이해하고 있다면 NL조인을 이해하는 것은 어렵지 않다.
다른 테이블의 기본키를 외래키로 가지고 있으면, 드라이빙 테이블의 인덱스를 해당 컬럼을 외래키로 가지고 있는 레코드의 블록에 대한 주소를 포인터로 가지고 있으며, 해당 블록을 읽어들여 두 레코드를 합치는 것이 NL 조인의 기본 원리이다.
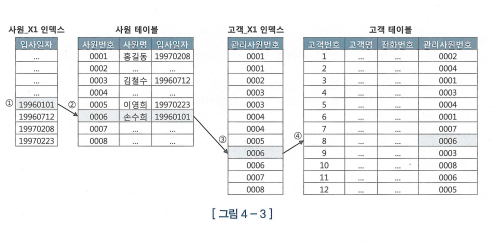
'친절한 SQL 튜닝' 책에 설명해주는 NL 조인의 원리이다. 인덱스는 디스크에 존재하는 블록을 최소한으로 읽기 위한 방법이다. 인덱스는 블록을 최소한으로 읽기 위한 방법 중 하나 일 뿐 항상 인덱스가 좋은 것은 아니다.
NL 조인은 랜덤 액세스 위주의 조인 방식이다. NL 조인은 레코드 하나를 읽더라도 블록 하나를 통째로 읽어야한다는 비효율성이 존재한다. 랜덤 액세스 방식이 아무리 빠르더라해도 대량의 데이터를 조인할 경우에는 불리한 이유이다.
또한, 한 레코드씩 순차적으로 진행한다는 점이다. 아무리 큰 테이블을 조인하더라도 인덱스를 타고 가서 데이터가 들어있는 블록을 한번에 가져오므로 매우 빠른 응답 속도를 낼수 있다. 그래서 OLTP 시스템에서 좋은 성능을 보여준다.
버퍼풀 구조를 이해하고 있다면, 인덱스를 타고 가서 데이터를 조회할 경우, MRU와 LRU사이로 데이터가 들어가게 된다. 그래서 버퍼풀에 더 오래 남을 수 있다. 하지만 시퀀셜 I/O일 경우 LRU 밑에서 데이터를 집어넣어서 데이터가 오래 남을 수 없다.
[ 소트 머지 조인 ]
조인하는 컬럼에 인덱스가 없을 경우, 대량 데이터 조인이어서 인덱스가 효과적이지 않을 경우 옵티마이저는 NL 조인보다 소트 머지 조인이나 해시 조인을 선택한다. 해시 조인이 등장하면서 예전보다 활발히 사용되고 있지는 않지만, 해시 조인을 사용할 수 없는 경우에 소트 머지 조인이 사용된다.
NL 조인과 소트 머지 조인의 방식은 거의 똑같다고 볼 수 있다. 차이점은 Sort Area에 미리 정렬해 둔 자료구조를 이용한다는 점만 다를 뿐 조인 프로세싱 자체는 NL조인과 같다. 그러면 성능 차이는 어디서 나는지 궁금할 수 있다.
NL 조인은 인덱스를 이용한 조인 방식이다. 조인 과정에서 데이터가 버퍼 캐시에 없는 경우가 건건히 있을 수 있다.
이때 데이터가 많아질수록, 디스크 조회 횟수가 많아지게 된다. select * from member을 할 경우에도 시퀀셜 i/o가 일어나는 이유와 같다고 볼 수 있다.
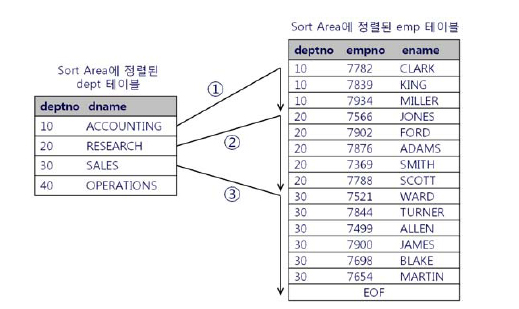
소트 머지 조인은 다음과 같은 상황에서 주로 사용된다.
1. 조인 조건식이 등치 조건이 아닌 대량 데이터 조인.
2. 조인 조건식이 아예 없는 조인( Cross Join, 카티션 프로덕트 )
소트 머지 조인은 조인을 위해 실시간으로 인덱스를 생성하는 것과 다름없다. 양쪽 집합을 정렬한 다음, NL 조인과 같은 방식으로 진행되지만,PGA 영역에 저장한 데이터를 이용하기 때문에 빠르다. 또한 스캔 위주의 액세스 방식을 사용한다는 점도 중요한 특징이다. 하지만 모든 처리가 스캔 방식으로 이루어지진 않는다. 양쪽 소스 집합으로부터 조인 대상 레코드를 찾는데는 인덱스를 이용할 수 있고, 랜덤 액세스가 일어난다.
[ 해시 조인 ]
소트 ㅈ머지 조인은 항상 양쪽 테이블을 정렬하는데 비용이 든다, 해시 조인은 그런 부담이 없다. 그렇다고 해서 모든 조인을 해시 조인을 해시 조인으로 처리할 수는 없다. 각 조인의 특성을 정확히 이해함으로써 상황에 맞게 선택하는 것이 중요하다.
해시 조인은 다음과 같은 2가지 단계로 진행된다.
1. Build : 작은 쪽 테이블을 읽어 해시 테이블을 생성한다.
조건에 해당하는 데이터를 읽어 해시 테이블을 생성한다. 이때, 조인 컬럼을 해시 테이블의 키 값으로 사용한다.
2. probe : 큰 쪽 테이블을 읽어 해시 테이블을 탐색하면서 조인한다.
조건에 해당하는 데이터를 읽어 조인 컬럼을 해시 함수에 넣고, 해시 체인을 스캔하면서 조인을 수행한다.
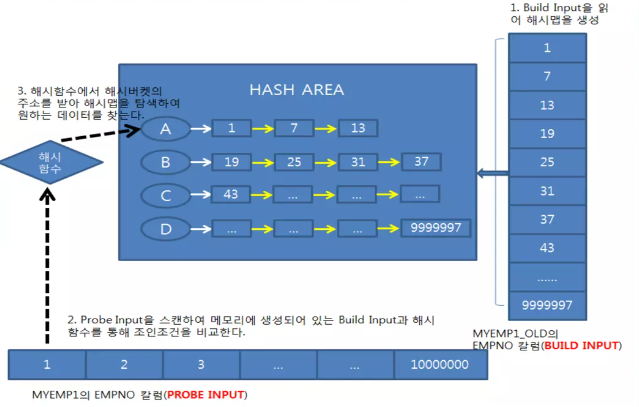
해시 조인이 소트 머지 조인보다 빠른 이유는 두 테이블 중 작은 테이블을 읽어 해시 함수에 넣어, 소트 머지 조인보다 부하가 적다. 또한,한쪽만 해시 테이블을 만들기 때문에 양쪽을 정렬하는 소트 머지 조인보다 부하가 적다/.
정리하자면 해시 조인은 NL 조인처럼 조인 과정에서 발생하는 랜덤 액세스 부하가 없고, 소트 머지 조인처럼 양쪽 집합을 미리 정렬하는 부하도 없다. 해시 테이블을 생성하는 비용이 들어가지만, 둘 중 작은 집합을 선택하므로 부담이 크지 않다. 해시 테이블이 PGA 메모리에 들어갈 때, 인메모리 해시 조인일 경우 가장 효과적이다.
설령 PGA에 해시 테이블이 다 들어가지 않더라도 소트 머지 조인보다 빠르다.
[ 조인 선택 기준 ]
데이터 크기에 따른 선택
1. 데이터가 적을 경우 > NL 조인
2. 데이터가 많을 경우 > 해시 조인
3. 데이터가 많을 조인인데, 해시 조인으로 처리할 수 없을 경우, 조인 조건식이 등치(=)조건이 아닐 경우 > 소트 머지 조인
수행 빈도에 따른 선택
1. NL 조인과 해시 조인 성능이 같을 경우 > NL 조인
2. 해시 조인이 약간 더 빠를 경우 > NL 조인
3. NL 조인보다 해시 조인이 매우 빠른 경우 > 해시 조인 // 데이터가 큰 경우. Infomation schema에 따른 통계 정보를 의존
'데이터베이스' 카테고리의 다른 글
| 계층 쿼리 (0) | 2023.10.03 |
|---|---|
| 트랜잭션 데이터 저장 과정, Direct Path Insert, Delete 과정 (0) | 2023.06.25 |
| jdbc 탐구하기 (0) | 2023.06.18 |
| postgresql의 운영에 필요한 테이블과 wait event (1) | 2023.06.11 |
| 데이터베이스 sequential, scattered (0) | 2023.06.08 |


