목적
데이터베이스를 어떻게 하면 좀 더 잘 설계를 할 수 있을까??? 라는 질문에서 계속 궁금증이 생겨서 글을 작성한다.
쿼리가 어떤 것이 효율적인지 실행 계획을 분석하다가 정리할겸 글을 작성한다.
글에 바탕이 되는 데이터베이스는 Postgresql이고, DBeaver를 사용했다.
선행 지식
- 관계 대수
관계 대수를 프로그래밍 언어처럼 구성한 것이 SQL이고, 다음과 같은 종류가 있다.
Selection: 선택 연산은 일반적으로 입력 릴레이션의 튜플 수에 비례한다. 따라서 선택 조건의 복잡도에 따라 비용이 결정된다.
Projection: 투영 연산은 일반적으로 입력 릴레이션의 크기에 비례한다. 따라서 입력 릴레이션의 크기가 작으면 비용이 낮아진다.
Union: Union 연산은 입력 릴레이션의 크기에 비례한다. 입력 릴레이션의 크기가 클수록 비용이 높아진다.
Set difference: 차집합 연산은 입력 릴레이션의 크기에 비례한다. 입력 릴레이션의 크기가 클수록 비용이 높아진다.
Cartesian product: 카테시안 곱 연산은 입력 릴레이션의 크기를 곱한 것과 같은 비용이 든다. 따라서 입력 릴레이션의 크기가 클수록 비용이 급격히 증가한다.
Join: 조인 연산은 입력 릴레이션의 크기와 조인 조건의 복잡도에 따라 결정됩니다. 일반적으로, 조인 조건이 단순할수록 비용이 낮아진다. 또한, 입력 릴레이션의 크기가 클수록 비용이 높아진다.
Projection : SELECT column_name FROM table_name;
Selection : SELECT * FROM table_name WHERE condition;
Join : SELECT * FROM table_name1 JOIN table_name2 ON condition;
Cartesian product : SELECT * FROM table_name1, table_name2;
Union : SELECT * FROM table_name1 UNION SELECT * FROM table_name2;
Set Difference : SELECT * FROM table_name1 WHERE NOT EXISTS (SELECT * FROM table_name2 WHERE condition);관계 대수의 비용은 다음과 같다.
Cartesian product: 두 테이블의 크기를 곱한 값이 비용. 1000 x 1000 = 1,000,000
Join: 조인 조건에 따라서 비용이 달라질 수 있다. 만약 기본 키와 외래 키 관계가 있는 경우에는 해당 조건을 이용해서 조인을 할 수 있으므로, 비용은 입력 릴레이션의 크기에 비례한다. 따라서, 비용은 1000입니다.
Projection: 투영 연산의 비용은 입력 릴레이션의 크기와 투영되는 컬럼의 수에 비례한다. 따라서, 투영 컬럼의 수에 따라서 비용이 결정된다.
Selection: 선택 연산의 비용은 선택 조건의 복잡도와 입력 릴레이션의 크기에 따라 결정된다. 일반적으로 선택 조건의 복잡도가 낮을수록 비용이 낮아진다.
Union: 두 테이블의 크기가 같으므로 비용은 1000.
Set difference: 입력 릴레이션의 크기에 비례하므로 비용은 1000.0. 쿼리가 실행되는 과정.
기초를 먼저 알고 가자. 쿼리는 어떤 과정으로 실행이 될까?
0. MySQL 인터페이스로 전달되어 MySQL 엔진에서 스토리지 엔진의 API에 요청할 명령을 만들어야한다.
1. 문법을 구분 분석을 진행하고 문장 구조를 파악한다.
- 학사때 프로그래밍 언어론을 들어봤으면 당연한 것이다.
2. 옵티마이저에 전달된다.
- 전달된 쿼리는 관계 대수로 해석되며 비용 기반 최적화가 진행된다.
3. 스토리지 엔진의 API에 요청이 전달되며 데이터를 가져와서 반환된다.
https://whiteman97.tistory.com/221
스토리지 엔진에서의 과정은 위 포스팅에서 찾아 본다.
1. 옵티마이저의 한계
최근 회사에 입사해서 쿼리만들고 있는데, 오기가 생겨 쿼리를 계속 날려보면서 옵티마이저의 멍청함과 한계를 절실히 느끼고 있다.

위 쿼리는 완벽하게 똑같은 결과를 도출하는 쿼리이다. 이렇게 간단한 쿼리는 옵티마이저가 알아서 최적화를 하므로 어떤 방식을 사용해도 똑같은 cost를 도출한다.
여기서 with 사용은 너무 남용이므로 쓰지 말자. 괜히 메모리만 잡아먹고 이점이 없다.
* 여기서 buffer cache 되어있는 데이터를 없다.
* 실행계획 분석에 buffer와는 관계가 없으므로 buffer는 무시하고 진행한다.
하지만 쿼리가 조금만 복잡해진다면??

위 쿼리도 똑같은 결과를 도출하는 쿼리이다. join이 몇개 들어갔을 뿐인데, 성능차이가 벌어지기 시작한다.
여기서 범위를 좀 더 넓혀보면 결과는 더욱 차이가 벌어진다.
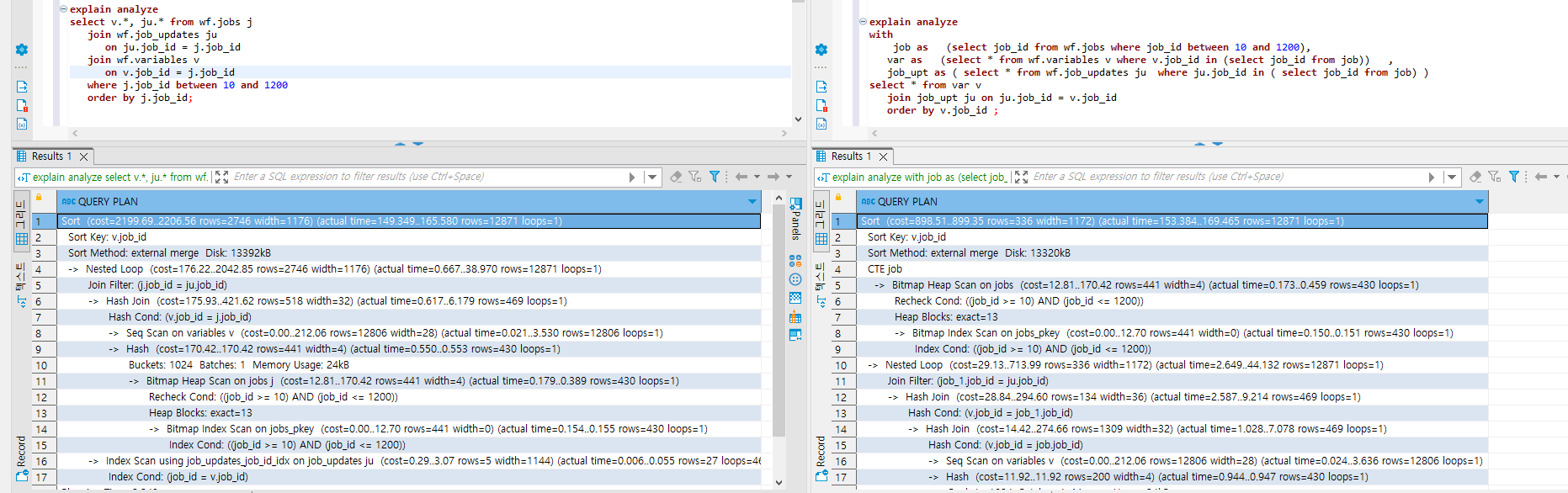
약 10% 차이가 나던게 거의 3배가량 차이가 벌어졌다.
물론, with문을 사용하는 오른쪽 쿼리가 메모리 사용량이 더 높겠지만, 옵티마이저의 한계를 절실히 보여주는 쿼리라고 생각한다.
여기서 DBA의 역량이 중요해진다. 쿼리를 어떻게 작성해야 좀 더 효율적인 쿼리가 되는지 예측할 수 있다.
(물론 나는 풀스택 개발자이므로, DBA로서 역량이 낮지만 개인적인 취미로 DB 공부를 열심히 하고 있다.
NETDB 형님들,, 잘 살고 계십니까 ㅠㅠ... 그때가 재밌었죠....)
2. 실행 계획을 분석하고 읽어보자!
-- 쿼리 --
* 디비는 회사 디비를 사용했으므로 ERD는 비공개한다.
explain analyze
with
job as (select job_id from wf.jobs where job_id between 10 and 1200),
var as (select * from wf.variables v where v.job_id in (select job_id from job)) ,
job_upt as ( select * from wf.job_updates ju where ju.job_id in ( select job_id from job))
select * from var v
join job_upt ju on ju.job_id = v.job_id
order by v.job_id ;쿼리가 7줄 밖에 안되는데 실행 계획은 엄~~~청 길다..ㅠㅠ
Sort (cost=898.51..899.35 rows=336 width=1172) (actual time=142.932..158.357 rows=12871 loops=1)
Sort Key: v.job_id
Sort Method: external merge Disk: 13320kB
CTE job
-> Bitmap Heap Scan on jobs (cost=12.81..170.42 rows=441 width=4) (actual time=0.110..0.243 rows=430 loops=1)
Recheck Cond: ((job_id >= 10) AND (job_id <= 1200))
Heap Blocks: exact=13
-> Bitmap Index Scan on jobs_pkey (cost=0.00..12.70 rows=441 width=0) (actual time=0.086..0.087 rows=430 loops=1)
Index Cond: ((job_id >= 10) AND (job_id <= 1200))
-> Nested Loop (cost=29.13..713.99 rows=336 width=1172) (actual time=1.513..38.095 rows=12871 loops=1)
Join Filter: (job_1.job_id = ju.job_id)
-> Hash Join (cost=28.84..294.60 rows=134 width=36) (actual time=1.464..7.331 rows=469 loops=1)
Hash Cond: (v.job_id = job_1.job_id)
-> Hash Join (cost=14.42..274.66 rows=1309 width=32) (actual time=0.549..5.976 rows=469 loops=1)
Hash Cond: (v.job_id = job.job_id)
-> Seq Scan on variables v (cost=0.00..212.06 rows=12806 width=28) (actual time=0.018..3.364 rows=12806 loops=1)
-> Hash (cost=11.92..11.92 rows=200 width=4) (actual time=0.503..0.506 rows=430 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 24kB
-> HashAggregate (cost=9.92..11.92 rows=200 width=4) (actual time=0.296..0.366 rows=430 loops=1)
Group Key: job.job_id
Batches: 1 Memory Usage: 77kB
-> CTE Scan on job (cost=0.00..8.82 rows=441 width=4) (actual time=0.001..0.061 rows=430 loops=1)
-> Hash (cost=11.92..11.92 rows=200 width=4) (actual time=0.875..0.877 rows=430 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 24kB
-> HashAggregate (cost=9.92..11.92 rows=200 width=4) (actual time=0.662..0.733 rows=430 loops=1)
Group Key: job_1.job_id
Batches: 1 Memory Usage: 77kB
-> CTE Scan on job job_1 (cost=0.00..8.82 rows=441 width=4) (actual time=0.116..0.412 rows=430 loops=1)
-> Index Scan using job_updates_job_id_idx on job_updates ju (cost=0.29..3.07 rows=5 width=1144) (actual time=0.006..0.051 rows=27 loops=469)
Index Cond: (job_id = v.job_id)
Planning Time: 2.248 ms
Execution Time: 163.338 ms여기서 중요한 단어를 좀 뽑아보자!
cost - 연산에 들어가는 비용이다.
옵티마이저의 기법은 2가지가 있다. 룰기반, 비용기반. 요즘에는 전부 비용기반으로 넘어가는 추세이다.
물론, 비용 산정은 '추정'일 뿐이다. 데이터베이스 옵티마이저는 테이블 및 인덱스의 통계 정보와 데이터 분포에 의존적이기 때문에 '추정'일 뿐이며 cost가 적게 나온다고 무조건 빠른 쿼리를 보장하지는 않는다.
- 통계 정보 부족: 옵티마이저는 쿼리 실행 계획을 선택하기 위해 테이블 및 인덱스에 대한 통계 정보를 사용합니다. 그러나 이러한 통계 정보가 부족하거나 오래된 경우, 옵티마이저는 최적의 실행 계획을 선택하기 어렵습니다.
- 쿼리 복잡도: 쿼리가 복잡해질수록 옵티마이저는 최적의 실행 계획을 선택하기 어려워집니다. 이는 쿼리에 조인, 서브쿼리 및 복잡한 WHERE 절 등이 포함된 경우에 특히 더 나타납니다.
- 데이터 분포 불균형: 특정 값의 분포가 고르지 않은 경우, 인덱스를 사용하는 것보다 테이블 풀 스캔이 더 효율적일 수 있습니다. 그러나 이러한 경우에도 옵티마이저는 인덱스를 사용하려고 시도합니다.
- 서브쿼리 처리: 서브쿼리는 쿼리 실행 계획을 선택하는 데 어려움을 초래할 수 있습니다. 서브쿼리는 최적의 실행 순서 및 연산 순서를 결정하기 어렵고, 서브쿼리의 결과를 임시 테이블로 저장해야 할 수도 있습니다.
- 동적 SQL: 동적 SQL을 사용하는 경우, 옵티마이저는 쿼리 실행 계획을 미리 계산할 수 없기 때문에 최적의 실행 계획을 선택하기 어려울 수 있습니다.
Bitmap hash scan ( Bitmap scan ), Heap Blocks
다소 생소한 이름이다. bit(0,1)map scan... 뭔 소린지 하나도 모르겠다. 0과 1로 이루어진 map(지도)를 만들어서 스캔한다? 아무리 봐도 모르겠다.
bitmap은 각 레코드의 존재 여부를 0,1로 표현한 이진 비트 배열이다.
예를들어 1,3,5번 레코드가 존재하고 2,4번 레코드가 없으면 ( 1 0 1 0 1 ) 이런 형식으로 표현된다.
bitmap scan은 인덱스 스캔과 풀스캔의 중간 정도에 사용되는 스캔 방식이다. 과도한 랜덤io를 방지하면서 인덱스의 성능도 어느정도 사용하는 것을 의미한다.
bitmap scan은 다음과 같은 순서로 일어난다.
1. 사용한 인덱스를 선택한다.
2. 인덱스를 통해 모든 행의 위치를 알아낸다.
3. bitmap을 만든다.
4. bitmap을 사용하여 테이블을 순회하고 조건에 맞는 행을 선택한다.
Nested Loop ( NL )
2개 이상의 테이블 ( 드라이빙, 드리븐 )에서 하나의 집합을 기준으로 순차적으로 드리븐 테이블의 row를 결합하여 원하는 결과를 도출해내는 방식이다.
데이터베이스를 공부하다보면 다음과 같은 사진을 많이 봤을 것이다.
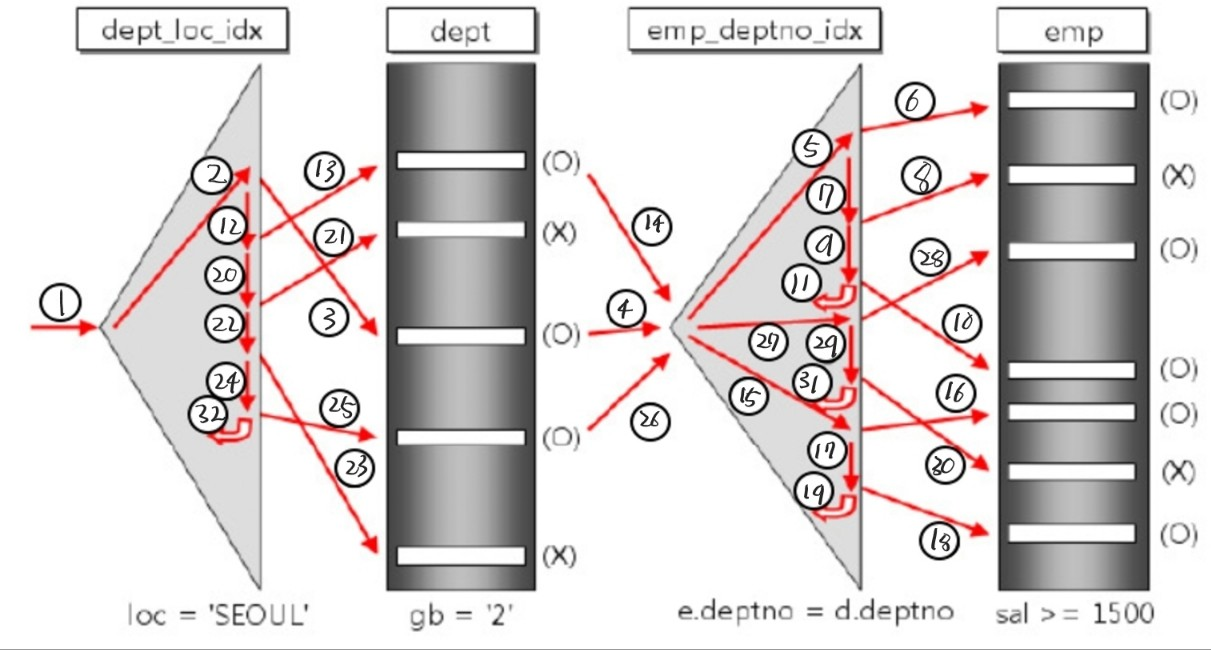
이 사진은 NL JOIN의 과정을 나타낸 것이다.
인덱스에 대한 랜덤 엑세스를 기반으로 하므로 대량의 데이터 처리에는 적합하지 않다.
앞서 오는 드라이빙 테이블은 데이터가 적거나 WHERE 절로 ROW의 수를 줄일 수 있는 테이블이어야 과정이 조금이라도 줄어든다.
드리븐 테이블은 드라이빙 테이블의 PK를 외래키로 가지고 있어야 좋다. 아니면 조인을 위해 적절한 인덱스가 생성되어 있어야한다.
만약 적절하게 인덱스가 설정되어 있지 않은 경우에는 COST가 M*N이 되므로 시간이 매우 오래걸릴 것이다.
Hash Join, Hash Cond
https://dev.mysql.com/blog-archive/hash-join-in-mysql-8/
PGA : 프로세스에 대한 데이터와 제어정보가 포함된 비 공유 메모리 영역
요약.
1. 빌드
a,b 테이블을 조인할때, 둘 중 더 작은 테이블의 조인하는 컬럼을 hash function을 통해 해시테이블을 만든다.
2. 프로브
더 큰 테이블을 순회하면서 해시 테이블에 key값이 있는지 순회한다.
key가 존재한다면, value찾아 조인을한다.
*주의 : 해시 테이블이 너무 커져서 PGA 영역보다 초과한다면 디스크 I/O가 발생하기 때문에 성능이 저하된다.
HashAggregate
말 그대로 해시 테이블을 이용하여 중간 집계를 하고, 결과를 다시 처리하여 최종 집계를 생성한다.
1. 입력 데이터가 해시 함수에 전달되고, 이 함수는 해시 키를 생성한다.
2. 생성된 해시 키를 기준으로 해시 테이블에 중간 결과를 저장한다.
3. 모든 입력 데이터가 처리되면, 각 해시 버킷의 중간 결과를 집계하여 최종 결과를 생성한다.
메모리에 중간 결과를 저장하므로 메모리 사용량이 높다.
Seq Scan
Full Scan으로도 불리며, 이름에서 알 수 있듯이 순차적으로 테이블을 순회한다.
많은 양의 데이터를 가져올 때 효율적이다.
CTE Scan, CTE JOB
with문을 사용해 view ( CTE )를 만들면 CTE 스캔이 된다.
메모리에 VIEW를 저장하는 휘발성이므로 메모리 사용량이 높다.
데이터베이스에서 메모리가 중요한 이유.
위에서 계속 실행계획을 설명하면서 나오는 말이 '메모리 사용량이 많다'는 말이다.
또, 쿼리에서 뿐만 아니라 자주 사용되는 페이지를 버퍼에 저장할 경우에도 메모리를 많이 사용하기 때문에 데이터베이스에서 중요한 수단이다.
VIEW가 SUBQUERY보다 일반적인 경우에 데이터를 캐싱하여 성능은 좋겠지만, 너무 많은 VIEW를 남용하게 되면, 메모리를 과하게 사용하므로 성능저하가 발생할 수 있다.
with, Subquery
둘 모두 똑같은 결과를 만들 수 있는 문법이지만 결정적 차이가 존재한다. 쿼리가 'caching'하는가? 이다.
여기서 VIEW ( 임시 테이블, 가상 테이블, CTE(Common Table Expression) 등 여러 용어로 불린다. )라는 개념을 알고 넘어가야한다.
VIEW란 무었일까?
자주 사용되는 쿼리를 캐싱하여 여러번 요청하지 않게 하는 기술이다. 메모리상에 적재되고, 임시 테이블의 이름을 지정하여 이름으로 쿼리 재사용이 가능하다.결론
1. WITH은 메모리에 caching되고, subquery는 그렇지 않다.
2. subquery는 메인쿼리와 같이 실행계획을 세우지만, with은 그렇지 않다.
쿼리 최적화 진행해보기.
explain analyze
with
jobs as ( select * from wf.jobs j where job_id between 10 and 200),
job_upts as (
select * from wf.job_updates ju where ju.job_upt_id in (
select job_upt_id from jobs
)
),
task_upts as (
select * from wf.task_updates tu where tu.job_upt_id in (
select ju.job_upt_id from job_upts ju
)
),
var2task_upts as (
select vtu.* from wf.variable2task_updates vtu join task_upts using (task_upt_id)
),
tasks as (
select *, (select jsonb_agg(v2t.*) as v2t_conn from var2task_upts v2t where t.task_upt_id = v2t.task_upt_id) from wf.tasks t
join task_upts using (task_id)
where t.task_id in ( select task_id from task_upts)
),
var as (
select * from wf.variables v join wf.var_updates vu on vu.var_upt_id = v.var_upt_id where vu.job_upt_id in (
select job_upt_id from job_upts
)
),
tasks_and_task_updates as (
select t.* from tasks t join task_upts tu using(task_id)
),
job_and_job_updates as (
select * from jobs join job_upts using (job_upt_id)
)
select
j.*,
(select jsonb_agg(v.*) from var v) as var,
(select jsonb_agg(tatu.*) from tasks_and_task_updates tatu where tatu.job_upt_id = j.job_upt_id) as task
from job_and_job_updates j;위 쿼리에 대한 비용은 다음과 같다.
GroupAggregate (cost=41223.40..42238.75 rows=11604 width=1708) (actual time=4053.422..14261.701 rows=431 loops=1)
Group Key: j.job_id, j.title, j.job_desc, j.job_type, j.grp_flg, j.grp_id, j.order_no, j.job_value, j.lock_flg, j.job_upt_id, j.upt_tm, j.del_tm, j.sng_flg, ju.job_upt_id, ju.job_upt_desc, ju.target_rto, ju.job_param_value, ju.del_tm, ju.conn_info, ju.job_id, ju.upt_user_id, ju.upt_tm
CTE jobs
-> Hash Join (cost=175.82..464.44 rows=438 width=135) (actual time=0.695..7.962 rows=430 loops=1)
Hash Cond: (j_1.job_id = jobs.job_id)
-> Seq Scan on jobs j_1 (cost=0.00..260.00 rows=10900 width=135) (actual time=0.028..4.405 rows=10900 loops=1)
-> Hash (cost=170.34..170.34 rows=438 width=4) (actual time=0.597..0.600 rows=430 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 24kB
-> Bitmap Heap Scan on jobs (cost=12.77..170.34 rows=438 width=4) (actual time=0.200..0.388 rows=430 loops=1)
Recheck Cond: ((job_id >= 10) AND (job_id <= 1000))
Heap Blocks: exact=13
-> Bitmap Index Scan on jobs_pkey (cost=0.00..12.66 rows=438 width=0) (actual time=0.172..0.172 rows=430 loops=1)
Index Cond: ((job_id >= 10) AND (job_id <= 1000))
CTE job_upts
-> Nested Loop (cost=10.14..1348.63 rows=438 width=1144) (actual time=9.325..15.348 rows=421 loops=1)
-> HashAggregate (cost=9.86..11.86 rows=200 width=4) (actual time=9.204..9.540 rows=422 loops=1)
Group Key: jobs_1.job_upt_id
Batches: 1 Memory Usage: 77kB
-> CTE Scan on jobs jobs_1 (cost=0.00..8.76 rows=438 width=4) (actual time=0.698..8.711 rows=430 loops=1)
-> Index Scan using job_updates_pkey on job_updates ju_1 (cost=0.29..6.75 rows=1 width=1144) (actual time=0.012..0.012 rows=1 loops=422)
Index Cond: (job_upt_id = jobs_1.job_upt_id)
CTE task_upts
-> Hash Join (cost=14.36..25122.14 rows=2420 width=608) (actual time=19.103..412.167 rows=2081 loops=1)
Hash Cond: (tu_2.job_upt_id = ju_2.job_upt_id)
-> Seq Scan on task_updates tu_2 (cost=0.00..24359.20 rows=274920 width=608) (actual time=0.075..344.031 rows=274920 loops=1)
-> Hash (cost=11.86..11.86 rows=200 width=4) (actual time=18.781..18.815 rows=421 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 23kB
-> HashAggregate (cost=9.86..11.86 rows=200 width=4) (actual time=18.421..18.559 rows=421 loops=1)
Group Key: ju_2.job_upt_id
Batches: 1 Memory Usage: 77kB
-> CTE Scan on job_upts ju_2 (cost=0.00..8.76 rows=438 width=4) (actual time=9.331..17.671 rows=421 loops=1)
-> Sort (cost=14288.18..14317.19 rows=11604 width=1708) (actual time=4052.791..4927.390 rows=38621 loops=1)
Sort Key: j.job_id, j.title, j.job_desc, j.job_type, j.grp_flg, j.grp_id, j.order_no, j.job_value, j.lock_flg, j.job_upt_id, j.upt_tm, j.del_tm, j.sng_flg, ju.job_upt_id, ju.job_upt_desc, ju.target_rto, ju.job_param_value, ju.del_tm, ju.conn_info, ju.job_id, ju.upt_user_id, ju.upt_tm
Sort Method: external merge Disk: 92368kB
-> Hash Full Join (cost=4580.14..4894.77 rows=11604 width=1708) (actual time=600.736..713.782 rows=38621 loops=1)
Hash Cond: (tu.task_upt_id = vtu.task_upt_id)
-> Hash Full Join (cost=3452.09..3711.27 rows=11604 width=1680) (actual time=144.704..220.631 rows=34625 loops=1)
Hash Cond: (j.job_id = v.job_id)
-> Merge Full Join (cost=1733.66..1912.52 rows=11604 width=1648) (actual time=86.569..124.921 rows=19371 loops=1)
Merge Cond: (ju.job_upt_id = tu.job_upt_id)
-> Sort (cost=1549.25..1551.65 rows=959 width=1612) (actual time=78.381..83.471 rows=2091 loops=1)
Sort Key: ju.job_upt_id
Sort Method: external merge Disk: 3224kB
-> Hash Full Join (cost=1437.40..1501.75 rows=959 width=1612) (actual time=44.665..48.193 rows=2091 loops=1)
Hash Cond: (ju.job_upt_id = task_upts.job_upt_id)
-> Hash Full Join (cost=14.23..57.77 rows=959 width=1580) (actual time=1.207..2.299 rows=430 loops=1)
Hash Cond: (j.job_upt_id = ju.job_upt_id)
-> CTE Scan on jobs j (cost=0.00..8.76 rows=438 width=854) (actual time=0.001..0.303 rows=430 loops=1)
-> Hash (cost=8.76..8.76 rows=438 width=726) (actual time=1.140..1.142 rows=421 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 334kB
-> CTE Scan on job_upts ju (cost=0.00..8.76 rows=438 width=726) (actual time=0.003..0.297 rows=421 loops=1)
-> Hash (cost=1421.81..1421.81 rows=109 width=36) (actual time=43.377..43.383 rows=2081 loops=1)
Buckets: 4096 (originally 1024) Batches: 1 (originally 1) Memory Usage: 1405kB
-> Hash Join (cost=1363.24..1421.81 rows=109 width=36) (actual time=33.281..38.474 rows=2081 loops=1)
Hash Cond: ((task_upts.task_id)::text = (t.task_id)::text)
-> CTE Scan on task_upts (cost=0.00..48.40 rows=2420 width=662) (actual time=0.004..1.255 rows=2081 loops=1)
-> Hash (cost=1332.99..1332.99 rows=2420 width=115) (actual time=33.127..33.131 rows=2068 loops=1)
Buckets: 4096 Batches: 1 Memory Usage: 264kB
-> Hash Join (cost=58.95..1332.99 rows=2420 width=115) (actual time=6.164..31.298 rows=2068 loops=1)
Hash Cond: ((t.task_id)::text = (task_upts_1.task_id)::text)
-> Seq Scan on tasks t (cost=0.00..1105.50 rows=53950 width=57) (actual time=0.024..13.253 rows=53950 loops=1)
-> Hash (cost=56.45..56.45 rows=200 width=58) (actual time=6.075..6.077 rows=2068 loops=1)
Buckets: 4096 (originally 1024) Batches: 1 (originally 1) Memory Usage: 140kB
-> HashAggregate (cost=54.45..56.45 rows=200 width=58) (actual time=3.847..4.434 rows=2068 loops=1)
Group Key: (task_upts_1.task_id)::text
Batches: 1 Memory Usage: 385kB
-> CTE Scan on task_upts task_upts_1 (cost=0.00..48.40 rows=2420 width=58) (actual time=0.015..1.621 rows=2081 loops=1)
-> Sort (cost=184.41..190.46 rows=2420 width=40) (actual time=8.169..15.228 rows=19357 loops=1)
Sort Key: tu.job_upt_id
Sort Method: quicksort Memory: 1971kB
-> CTE Scan on task_upts tu (cost=0.00..48.40 rows=2420 width=40) (actual time=0.022..3.167 rows=2081 loops=1)
-> Hash (cost=1714.80..1714.80 rows=290 width=36) (actual time=58.081..58.088 rows=400 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 57kB
-> Hash Join (cost=1451.82..1714.80 rows=290 width=36) (actual time=48.383..57.611 rows=400 loops=1)
Hash Cond: (v.var_upt_id = vu.var_upt_id)
-> Seq Scan on variables v (cost=0.00..212.06 rows=12806 width=28) (actual time=0.025..6.318 rows=12806 loops=1)
-> Hash (cost=1433.57..1433.57 rows=1460 width=33) (actual time=48.251..48.255 rows=696 loops=1)
Buckets: 2048 Batches: 1 Memory Usage: 67kB
-> Hash Join (cost=14.36..1433.57 rows=1460 width=33) (actual time=36.774..47.551 rows=696 loops=1)
Hash Cond: (vu.job_upt_id = job_upts.job_upt_id)
-> Seq Scan on var_updates vu (cost=0.00..1233.52 rows=64552 width=33) (actual time=0.046..36.091 rows=64552 loops=1)
-> Hash (cost=11.86..11.86 rows=200 width=4) (actual time=0.687..0.689 rows=421 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 23kB
-> HashAggregate (cost=9.86..11.86 rows=200 width=4) (actual time=0.476..0.544 rows=421 loops=1)
Group Key: job_upts.job_upt_id
Batches: 1 Memory Usage: 77kB
-> CTE Scan on job_upts (cost=0.00..8.76 rows=438 width=4) (actual time=0.013..0.244 rows=421 loops=1)
-> Hash (cost=1080.79..1080.79 rows=3781 width=36) (actual time=455.927..455.931 rows=591 loops=1)
Buckets: 4096 Batches: 1 Memory Usage: 70kB
-> Hash Join (cost=58.95..1080.79 rows=3781 width=36) (actual time=423.318..455.568 rows=591 loops=1)
Hash Cond: (vtu.task_upt_id = tu_1.task_upt_id)
-> Seq Scan on variable2task_updates vtu (cost=0.00..829.08 rows=57408 width=36) (actual time=0.032..22.699 rows=57408 loops=1)
-> Hash (cost=56.45..56.45 rows=200 width=4) (actual time=423.172..423.174 rows=2081 loops=1)
Buckets: 4096 (originally 1024) Batches: 1 (originally 1) Memory Usage: 106kB
-> HashAggregate (cost=54.45..56.45 rows=200 width=4) (actual time=421.682..422.244 rows=2081 loops=1)
Group Key: tu_1.task_upt_id
Batches: 1 Memory Usage: 257kB
-> CTE Scan on task_upts tu_1 (cost=0.00..48.40 rows=2420 width=4) (actual time=19.111..419.092 rows=2081 loops=1)
Planning Time: 6.618 ms
Execution Time: 14291.356 ms읽어보면, grouping을 해주는데 비용이 엄청 많이 들어가는 것을 볼 수 있다.
데이터가 많아질수록 grouping에 대한 비용이 많이 들어가기 때문에, 더 많은 데이터를 가져오면 올수록 성능이 낮아진다.
쿼리를 바꿔보겠다.
explain analyze
with
jobs as ( select * from wf.jobs j where job_id between 10 and 1000),
job_upts as (
select * from wf.job_updates ju where ju.job_upt_id in (
select job_upt_id from jobs
)
),
task_upts as (
select * from wf.task_updates tu where tu.job_upt_id in (
select ju.job_upt_id from job_upts ju
)
),
var2task_upts as (
select vtu.* from wf.variable2task_updates vtu join task_upts using (task_upt_id)
),
tasks as (
select *, (select jsonb_agg(v2t.*) as v2t_conn from var2task_upts v2t where t.task_upt_id = v2t.task_upt_id) from wf.tasks t
join task_upts using (task_id)
where t.task_id in ( select task_id from task_upts)
),
var as (
select * from wf.variables v join wf.var_updates vu on vu.var_upt_id = v.var_upt_id where vu.job_upt_id in (
select job_upt_id from job_upts
)
),
tasks_and_task_updates as (
select t.* from tasks t join task_upts tu using(task_id)
),
job_and_job_updates as (
select * from jobs join job_upts using (job_upt_id)
)
select
j.*,
(select jsonb_agg(v.*) from var v) as var,
(select jsonb_agg(tatu.*) from tasks_and_task_updates tatu where tatu.job_upt_id = j.job_upt_id) as task
from job_and_job_updates j;최대한 CTE를 활용하여 중복쿼리가 나가는 것을 제한시켰고, GROUP BY절을 없애므로써 데이터가 많든 적든 일관된 쿼리 성능을 보장할 수 있도록 만들어보았다.
Hash Join (cost=28370.89..1215128.98 rows=959 width=1640) (actual time=4046.258..17282.957 rows=421 loops=1)
Hash Cond: (jobs.job_upt_id = job_upts.job_upt_id)
CTE jobs
-> Bitmap Heap Scan on jobs j (cost=12.77..170.34 rows=438 width=135) (actual time=0.194..0.394 rows=430 loops=1)
Recheck Cond: ((job_id >= 10) AND (job_id <= 1000))
Heap Blocks: exact=13
-> Bitmap Index Scan on jobs_pkey (cost=0.00..12.66 rows=438 width=0) (actual time=0.170..0.171 rows=430 loops=1)
Index Cond: ((job_id >= 10) AND (job_id <= 1000))
CTE job_upts
-> Nested Loop (cost=10.14..1348.63 rows=438 width=1144) (actual time=3506.094..3510.960 rows=421 loops=1)
-> HashAggregate (cost=9.86..11.86 rows=200 width=4) (actual time=3505.968..3506.562 rows=422 loops=1)
Group Key: jobs_1.job_upt_id
Batches: 1 Memory Usage: 77kB
-> CTE Scan on jobs jobs_1 (cost=0.00..8.76 rows=438 width=4) (actual time=0.001..0.563 rows=430 loops=1)
-> Index Scan using job_updates_pkey on job_updates ju (cost=0.29..6.75 rows=1 width=1144) (actual time=0.008..0.008 rows=1 loops=422)
Index Cond: (job_upt_id = jobs_1.job_upt_id)
CTE task_upts
-> Hash Join (cost=14.36..25122.14 rows=2420 width=608) (actual time=0.977..460.793 rows=2081 loops=1)
Hash Cond: (tu.job_upt_id = ju_1.job_upt_id)
-> Seq Scan on task_updates tu (cost=0.00..24359.20 rows=274920 width=608) (actual time=0.056..392.760 rows=274920 loops=1)
-> Hash (cost=11.86..11.86 rows=200 width=4) (actual time=0.756..0.758 rows=421 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 23kB
-> HashAggregate (cost=9.86..11.86 rows=200 width=4) (actual time=0.427..0.497 rows=421 loops=1)
Group Key: ju_1.job_upt_id
Batches: 1 Memory Usage: 77kB
-> CTE Scan on job_upts ju_1 (cost=0.00..8.76 rows=438 width=4) (actual time=0.009..0.222 rows=421 loops=1)
InitPlan 4 (returns $4)
-> Aggregate (cost=1715.53..1715.54 rows=1 width=32) (actual time=50.980..50.986 rows=1 loops=1)
-> Hash Join (cost=1451.82..1714.80 rows=290 width=61) (actual time=36.060..40.241 rows=400 loops=1)
Hash Cond: (v.var_upt_id = vu.var_upt_id)
-> Seq Scan on variables v (cost=0.00..212.06 rows=12806 width=28) (actual time=0.048..2.388 rows=12806 loops=1)
-> Hash (cost=1433.57..1433.57 rows=1460 width=33) (actual time=35.912..35.916 rows=696 loops=1)
Buckets: 2048 Batches: 1 Memory Usage: 68kB
-> Hash Join (cost=14.36..1433.57 rows=1460 width=33) (actual time=30.262..35.422 rows=696 loops=1)
Hash Cond: (vu.job_upt_id = job_upts_1.job_upt_id)
-> Seq Scan on var_updates vu (cost=0.00..1233.52 rows=64552 width=33) (actual time=0.073..23.957 rows=64552 loops=1)
-> Hash (cost=11.86..11.86 rows=200 width=4) (actual time=1.131..1.132 rows=421 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 23kB
-> HashAggregate (cost=9.86..11.86 rows=200 width=4) (actual time=0.712..0.867 rows=421 loops=1)
Group Key: job_upts_1.job_upt_id
Batches: 1 Memory Usage: 77kB
-> CTE Scan on job_upts job_upts_1 (cost=0.00..8.76 rows=438 width=4) (actual time=0.023..0.346 rows=421 loops=1)
-> CTE Scan on jobs (cost=0.00..8.76 rows=438 width=854) (actual time=0.201..0.952 rows=430 loops=1)
-> Hash (cost=8.76..8.76 rows=438 width=726) (actual time=3515.715..3515.716 rows=421 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 335kB
-> CTE Scan on job_upts (cost=0.00..8.76 rows=438 width=726) (actual time=3506.112..3512.666 rows=421 loops=1)
SubPlan 6
-> Aggregate (cost=1237.44..1237.45 rows=1 width=32) (actual time=32.467..32.467 rows=1 loops=421)
-> Hash Join (cost=152.52..210.01 rows=1 width=661) (actual time=3.065..3.559 rows=5 loops=421)
Hash Cond: ((tu_1.task_id)::text = (t.task_id)::text)
-> CTE Scan on task_upts tu_1 (cost=0.00..48.40 rows=2420 width=58) (actual time=0.003..0.434 rows=2081 loops=420)
-> Hash (cost=152.51..152.51 rows=1 width=777) (actual time=2.733..2.733 rows=5 loops=421)
Buckets: 1024 Batches: 1 Memory Usage: 41kB
-> Nested Loop (cost=109.47..152.51 rows=1 width=777) (actual time=2.007..2.683 rows=5 loops=421)
Join Filter: ((task_upts_1.task_id)::text = (t.task_id)::text)
-> Hash Join (cost=109.05..111.92 rows=6 width=720) (actual time=1.943..2.579 rows=5 loops=421)
Hash Cond: ((task_upts_2.task_id)::text = (task_upts_1.task_id)::text)
-> HashAggregate (cost=54.45..56.45 rows=200 width=58) (actual time=0.013..0.566 rows=2068 loops=420)
Group Key: (task_upts_2.task_id)::text
Batches: 1 Memory Usage: 385kB
-> CTE Scan on task_upts task_upts_2 (cost=0.00..48.40 rows=2420 width=58) (actual time=0.052..1.685 rows=2081 loops=1)
-> Hash (cost=54.45..54.45 rows=12 width=662) (actual time=1.722..1.722 rows=5 loops=421)
Buckets: 1024 Batches: 1 Memory Usage: 37kB
-> CTE Scan on task_upts task_upts_1 (cost=0.00..54.45 rows=12 width=662) (actual time=0.280..1.673 rows=5 loops=421)
Filter: (job_upt_id = jobs.job_upt_id)
Rows Removed by Filter: 2076
-> Index Scan using tasks_pkey on tasks t (cost=0.41..6.75 rows=1 width=57) (actual time=0.011..0.011 rows=1 loops=2081)
Index Cond: ((task_id)::text = (task_upts_2.task_id)::text)
SubPlan 5
-> Aggregate (cost=1027.42..1027.43 rows=1 width=32) (actual time=5.567..5.567 rows=1 loops=2119)
-> Nested Loop (cost=0.00..1027.36 rows=24 width=8) (actual time=4.504..5.559 rows=0 loops=2119)
-> CTE Scan on task_upts (cost=0.00..54.45 rows=12 width=4) (actual time=0.307..0.657 rows=1 loops=2119)
Filter: (task_upt_id = t.task_upt_id)
Rows Removed by Filter: 2080
-> Materialize (cost=0.00..972.61 rows=2 width=8) (actual time=4.103..5.132 rows=0 loops=2018)
-> Seq Scan on variable2task_updates vtu (cost=0.00..972.60 rows=2 width=8) (actual time=4.091..5.120 rows=0 loops=2018)
Filter: (task_upt_id = t.task_upt_id)
Rows Removed by Filter: 57408
Planning Time: 4.150 ms
JIT:
Functions: 108
Options: Inlining true, Optimization true, Expressions true, Deforming true
Timing: Generation 18.917 ms, Inlining 29.911 ms, Optimization 2113.128 ms, Emission 1362.766 ms, Total 3524.723 ms
Execution Time: 17305.736 ms성능을 보면 많이 개선된 모습을 볼 수 있다.
처음하는 쿼리 튜닝이었는데, 이렇게 하는게 맞는지 잘 모르겠다.
COST가 낮다고 무조건 쿼리가 빨리 끝나지는 않는다.
explain analyze
SELECT j.*, ju.*, jsonb_agg(
jsonb_build_object(
'task', t.*,
'var', v.*,
'var_upt', vu.*,
'var2task', vtu.*
)
) AS task_and_var_updates
FROM wf.jobs j
JOIN wf.job_updates ju ON j.job_upt_id = ju.job_upt_id
JOIN wf.task_updates tu ON tu.job_upt_id = ju.job_upt_id
JOIN wf.tasks t ON tu.task_id = t.task_id
FULL OUTER JOIN wf.variable2task_updates vtu ON tu.task_upt_id = vtu.task_upt_id
FULL OUTER JOIN wf.variables v ON v.var_id = vtu.var_id
FULL OUTER JOIN wf.var_updates vu ON v.var_upt_id = vu.var_upt_id
WHERE j.job_id BETWEEN 10 AND 10000
GROUP BY j.job_id, ju.job_upt_id ;
위 쿼리에 대한 실행계획이다.
이전에 만들었던 쿼리보다 코스트가 20%는 더 높게 나왔지만, 쿼리 로그를 읽어보면, 'Gather Merge' 라는 플랜이 있다.
이 플랜은 병렬로 쿼리를 실행시켜, cpu에 대한 부하가 더 크지만 쿼리 실행은 훨씬 빠른 결과를 보여준다.
실행계획이란 메모리/디스크 i/o, 조인, 조건절, 릴레이션 크기, 복잡도, 쿼리 실행 시간를 요소를 고려한 항목이므로, cpu를 사용하면 cpu에 대한 비용이 많이 늘어나기 때문에 cost가 늘어나더라도 빠른 실행 결과를 보여준다.
GroupAggregate (cost=33860.90..34819.35 rows=6897 width=1311) (actual time=377.783..707.354 rows=1505 loops=1)
Group Key: j.job_id, ju.job_upt_id
-> Gather Merge (cost=33860.90..34664.17 rows=6897 width=1501) (actual time=377.613..403.158 rows=7297 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=32860.88..32868.06 rows=2874 width=1501) (actual time=336.870..340.639 rows=2432 loops=3)
Sort Key: j.job_id, ju.job_upt_id
Sort Method: external merge Disk: 3632kB
Worker 0: Sort Method: quicksort Memory: 2650kB
Worker 1: Sort Method: external merge Disk: 3152kB
-> Nested Loop Left Join (cost=2594.79..30816.28 rows=2874 width=1501) (actual time=91.794..310.171 rows=2432 loops=3)
-> Hash Left Join (cost=2594.50..29243.99 rows=2874 width=1448) (actual time=91.747..304.586 rows=2432 loops=3)
Hash Cond: (vtu.var_id = v.var_id)
-> Nested Loop (cost=2222.37..28864.31 rows=2874 width=1396) (actual time=75.856..286.089 rows=2432 loops=3)
-> Nested Loop (cost=2221.95..27586.35 rows=2874 width=1333) (actual time=75.733..259.414 rows=2432 loops=3)
Join Filter: (j.job_upt_id = ju.job_upt_id)
-> Hash Left Join (cost=2221.66..26070.68 rows=3333 width=193) (actual time=75.592..233.079 rows=2432 loops=3)
Hash Cond: (tu.task_upt_id = vtu.task_upt_id)
-> Hash Join (cost=225.98..23444.38 rows=3333 width=161) (actual time=3.237..142.587 rows=2371 loops=3)
Hash Cond: (tu.job_upt_id = j.job_upt_id)
-> Parallel Seq Scan on task_updates tu (cost=0.00..22755.50 rows=114550 width=26) (actual time=0.053..117.773 rows=91640 loops=3)
-> Hash (cost=207.87..207.87 rows=1449 width=135) (actual time=2.329..2.332 rows=1510 loops=3)
Buckets: 2048 Batches: 1 Memory Usage: 169kB
-> Bitmap Heap Scan on jobs j (cost=35.14..207.87 rows=1449 width=135) (actual time=0.355..1.181 rows=1519 loops=3)
Recheck Cond: ((job_id >= 10) AND (job_id <= 10000))
Heap Blocks: exact=41
-> Bitmap Index Scan on jobs_pkey (cost=0.00..34.77 rows=1449 width=0) (actual time=0.323..0.324 rows=1519 loops=3)
Index Cond: ((job_id >= 10) AND (job_id <= 10000))
-> Hash (cost=829.08..829.08 rows=57408 width=40) (actual time=70.842..70.843 rows=57408 loops=3)
Buckets: 65536 Batches: 2 Memory Usage: 2538kB
-> Seq Scan on variable2task_updates vtu (cost=0.00..829.08 rows=57408 width=40) (actual time=0.115..30.877 rows=57408 loops=3)
-> Index Scan using job_updates_pkey on job_updates ju (cost=0.29..0.44 rows=1 width=1144) (actual time=0.009..0.009 rows=1 loops=7297)
Index Cond: (job_upt_id = tu.job_upt_id)
-> Index Scan using tasks_pkey on tasks t (cost=0.41..0.44 rows=1 width=99) (actual time=0.009..0.009 rows=1 loops=7297)
Index Cond: ((task_id)::text = (tu.task_id)::text)
-> Hash (cost=212.06..212.06 rows=12806 width=60) (actual time=15.621..15.622 rows=12806 loops=3)
Buckets: 16384 Batches: 1 Memory Usage: 1207kB
-> Seq Scan on variables v (cost=0.00..212.06 rows=12806 width=60) (actual time=0.045..8.542 rows=12806 loops=3)
-> Index Scan using var_updates_pkey on var_updates vu (cost=0.29..0.55 rows=1 width=61) (actual time=0.001..0.001 rows=0 loops=7297)
Index Cond: (var_upt_id = v.var_upt_id)
Planning Time: 30.721 ms
Execution Time: 712.623 ms참고 자료
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=hdlee91&logNo=150170830657
PostgreSQL 9.2 인덱스 온리 스캔
참조 : http://www.techscore.com/blog/2013/05/27/postgresql-index-only-scan-%E5%A5%AE%E9%97%98%...
blog.naver.com
https://seungtaek-overflow.tistory.com/5
[PG] 쿼리 실행 계획 분석하기 - Table Scan
데이터베이스에 날릴 쿼리를 최적화하기 위해서는, 데이터베이스가 실제로 쿼리를 실행하는 방식과 해당 쿼리의 성능을 알고 있어야 한다. 그러기 위해서 데이터베이스의 쿼리 실행 계획(Query e
seungtaek-overflow.tistory.com
[PostgreSQL] PostgreSQL Vacuum 이란 ( FSM, VM, TID )
Vacuum 사전적의미로 청소, 진공, 공백을 의미합니다. PostgreSQL 에서 Vacuum 은 MVCC 에 의해 현재 사용되지 않는 이전의 저장된 값들을 정리합니다. Vacuum 을 하는 이유 PostgreSQL 은 MVCC 에 의해 이전의
mozi.tistory.com
https://blog.naver.com/PostView.naver?blogId=sssang97&logNo=222066082736
[PostgreSQL] Scan
Scan이란 말 그대로 데이터베이스를 스캔하는 것을 말한다. 기본적으로 관계형 데이터베이스들은 데이터를...
blog.naver.com
'데이터베이스' 카테고리의 다른 글
| postgresql mvcc (0) | 2023.05.20 |
|---|---|
| Postgresql's memory architecture (0) | 2023.05.13 |
| Delete vs Truncate (0) | 2023.04.26 |
| postgresql's sequence obejct (0) | 2023.03.28 |
| MySQL과 Postgresql의 차이 (1) | 2023.02.20 |

