캐시는 프로세서 내부에 있는 빠른 메모리로, 일반적으로 L1 캐시와 L2 캐시가 있습니다. L1 캐시는 프로세서 코어에 직접 연결되어 있으며, L2 캐시는 코어들 사이를 공유하는 공유 버스에 연결되어 있습니다. 캐시는 메모리보다 훨씬 빠르지만 용량은 작습니다.
반면에, 메모리(RAM)는 CPU보다 느리지만 용량이 크기 때문에, 프로그램에서 사용하는 데이터를 모두 캐시에 저장할 수 없습니다. 때문에, 프로그램이 변수를 읽거나 쓸 때, 해당 변수의 값을 캐시에서 읽어오거나 캐시에 저장할 수도 있습니다.
자바에서 volatile 키워드는 이러한 캐시와 메모리의 동기화를 보장하는 역할을 합니다. volatile 키워드가 붙은 변수는, 쓰기가 발생하면 해당 변수의 값을 바로 메모리에 써넣습니다. 또한, 다른 코어에서 해당 변수를 읽을 때는 캐시에서 읽지 않고 바로 메모리에서 값을 읽어오기 때문에 캐시 불일치 문제를 방지할 수 있습니다.
예를 들어, 다음과 같은 코드가 있다고 가정해봅시다.
public class Main {
private volatile int count = 0;
public void increment() {
count++;
}
public int getCount() {
return count;
}
}위 코드에서 count 변수는 volatile 키워드로 선언되어 있기 때문에, increment() 메소드에서 count 값을 증가시키는 경우, 항상 메모리에 값을 써넣습니다. 이후 다른 코어에서 getCount() 메소드를 호출하여 count 값을 읽을 때도, 메모리에서 값을 읽어오므로 항상 올바른 값을 반환할 수 있습니다. 이러한 동기화를 통해, 멀티코어 환경에서도 안전하게 변수를 공유할 수 있습니다.
CPU 캐시와 RAM 사이 동기화는 캐시 일관성 프로토콜(Cache Coherence Protocol)을 통해 이루어집니다. 캐시 일관성 프로토콜은 CPU 캐시와 메인 메모리 사이의 데이터 일관성을 유지하기 위한 알고리즘입니다.
캐시 일관성 프로토콜은 CPU 캐시에서 쓰기 작업이 발생하면 해당 데이터를 메모리에서 읽어와 캐시 라인에 기록합니다. 이때, 같은 메모리 위치를 다른 CPU에서 읽을 때, 캐시 일관성 프로토콜을 통해 각 CPU 캐시의 데이터가 일치하도록 유지합니다. 따라서, 다른 CPU가 해당 메모리 위치에 접근하면 해당 메모리 위치의 데이터가 메인 메모리에서 읽혀와 캐시에 기록됩니다.
즉, 캐시 일관성 프로토콜은 CPU 캐시와 메모리 사이의 데이터 일관성을 유지하기 위해 필요한 프로토콜이며, 이를 통해 캐시와 메모리의 데이터 일관성이 유지됩니다.
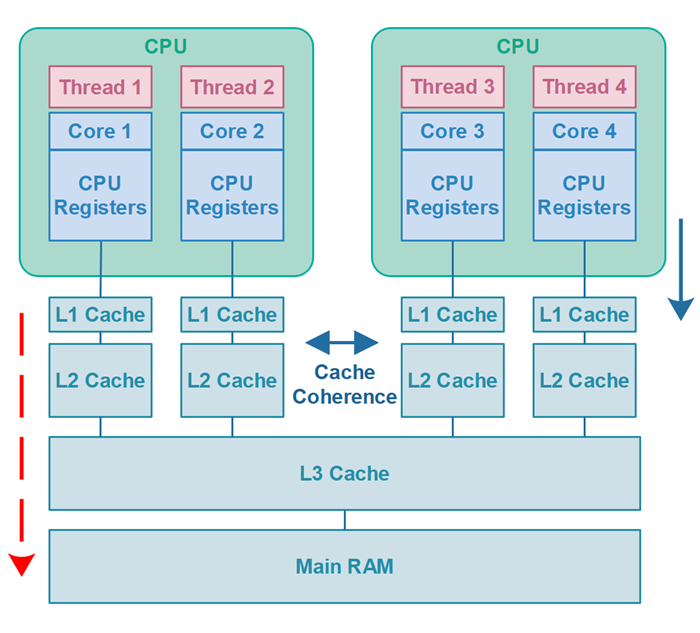
CPU 캐시는 일반적으로 세 가지 레벨로 나뉩니다. L1, L2 및 L3 캐시입니다. 각 레벨의 역할은 다음과 같습니다.
- L1 캐시: CPU 코어와 가장 가까운 캐시로, 가장 빠른 속도를 가지고 있습니다. 작은 용량이며, 반복적으로 사용되는 데이터를 저장하고 실행 중인 프로세스가 빠르게 액세스할 수 있습니다.
- L2 캐시: L1 캐시 바로 위에 위치하며, L1 캐시보다 용량이 큽니다. 더 느리지만 여전히 매우 빠르며 L1 캐시에서 참조하지 않은 데이터를 저장합니다.
- L3 캐시: L1, L2 캐시와 다른 물리적인 위치에 있으며, L2 캐시보다 더 큰 용량을 가지고 있습니다. CPU 코어 간 데이터 공유를 위해 사용됩니다.
CPU 캐시는 RAM보다 빠르지만 용량이 작기 때문에, 데이터가 CPU 캐시에 올라가면 성능이 향상됩니다. 그러나 CPU 캐시에 저장된 데이터는 RAM과 일치하지 않을 수 있으며, 이러한 불일치는 동기화 오버헤드를 유발할 수 있습니다. 이러한 동기화 오버헤드는 Java와 같은 고급 언어에서 발생하는 동시성 이슈를 유발할 수 있습니다. 따라서, 자바에서는 동시성 이슈를 다루기 위해 별도의 메모리 모델을 사용하고 있습니다.
volatile 키워드를 사용해야 하는 이유는 CPU이ㅡ 코어는 각 코어에 연결된 L1,L2 캐시를 참조하는데, A 코어의 L1,L2 캐시에 담긴 데이터는 B 코어에서 접근이 불가능 하기 때문에 volatile키워드를 사용하여 RAM에 데이터를 담아 해결한다는 의미이다.
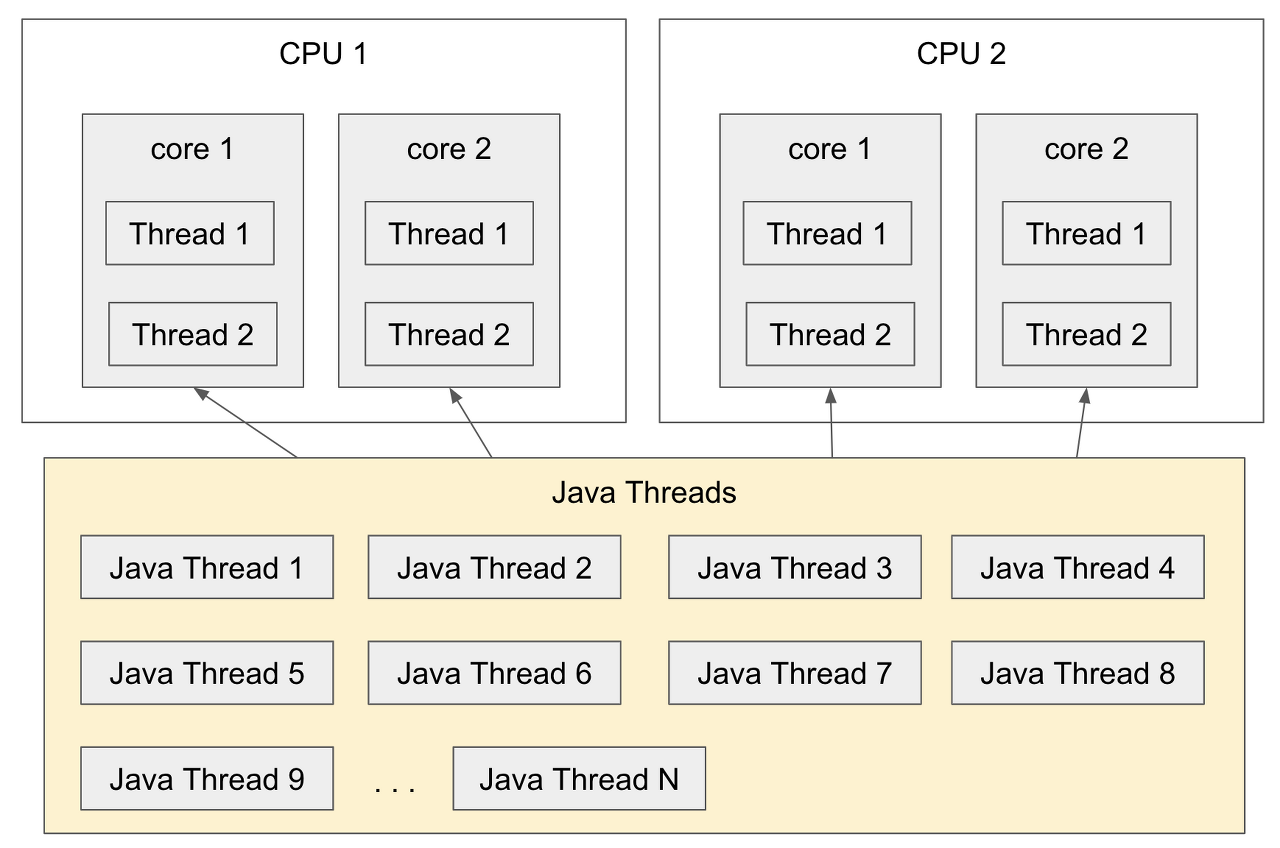
자바 스레드와 CPU의 스레드는 서로 다른 개념입니다.
자바에서의 스레드는 JVM에서 제어되는 개체(Object)입니다. 하나의 자바 프로세스에서 여러 개의 스레드를 생성하여 실행할 수 있습니다. 자바 스레드는 JVM에서 관리되는 스레드 스택과 PC(Program Counter) 레지스터 등의 정보로 이루어진 프로세스 내부의 개체(Object)입니다.
반면에 CPU의 스레드는 물리적인 개체입니다. CPU 내부에는 코어(Core)가 있고, 각 코어는 하나 이상의 물리적인 스레드를 가질 수 있습니다. 이러한 물리적인 스레드를 하이퍼스레딩(Hyper-Threading)이라고도 합니다. 하이퍼스레딩을 지원하는 CPU에서는 코어 하나가 여러 개의 물리적 스레드를 처리할 수 있기 때문에, CPU 사용률을 향상시킬 수 있습니다.
자바 스레드는 JVM에서 스케줄링되고, CPU의 스레드는 하드웨어에서 스케줄링됩니다. JVM은 자바 스레드를 CPU의 스레드에 매핑하여 실행시키는데, 이 때 매핑하는 방식에 따라 성능이 달라질 수 있습니다. 이러한 성능 이슈를 개선하기 위해 JDK 1.5부터는 "Thread Affinity" 기능을 제공합니다.
여기서 volatile 키워드를 사용하는 이유는 다음과 같습니다.
쓰레드 1은 running 변수를 참조할 때 자신의 CPU cache를 참조합니다.
쓰레드 2는 자신의 CPU cache의 running 변수를 false로 바꾼 것이기 때문에, 변수가 같음에도 불구하고 서로 다른 메모리 주소를 참조하게 되는것입니다.
'프로그래밍언어' 카테고리의 다른 글
| java8이전과 이후의 garbage collector의 동작과 종류 (0) | 2023.03.26 |
|---|---|
| 싱글톤과 플라이웨이트 패턴 (1) | 2023.03.13 |
| 자바의 Object Class (0) | 2023.02.10 |
| deep copy, shallow copy, String, Heap, Stack, Immutable, mutable (0) | 2023.02.10 |
| JIT 컴파일러 (0) | 2022.12.26 |


