프로젝트 도중 hbase에 데이터를 넣어야하는데, 골머리를 앓고 있다.
기존에 사용하던 Mongodb, elasticsearch, mysql 등 데이터베이스와 너무 다르다.
자동으로 생성해주던 pk에 대한 audo increment도 없고, 데이터베이스에 테이블을 나눠야하는데 테이블도 없고,,,
못보던 컬럼패밀리도 있고,,,, cell에 대한 개념도 없어서 일단 정리를 하려고 한다.

hbase table 구조
HMaster - 도서관
Region server - 대분류
Region - 작은 구역
column family - rdbms에서 테이블이랑 똑같은 듯. / 도서
column qualifier - 컬럼 명
family + qualifier = column
cell = 각 row의 column에 대한 데이터 하나의 조각
-------
hbase의 thrift library를 이용하기 위해서는 thrift server를 켜야함. 파이썬, 자바, 스칼라 등 다양한 library를 지원함.
hbase-daemon.sh start thrift -p 포트번호
--- python 코드
import happybase
CDH6_HBASE_THRIFT_VER='0.92'
hbase_cnxn = happybase.Connection( # 커넥션 생성
host='192.168.56.101', port=9090,
table_prefix_separator=b'_',
timeout=None,
autoconnect=True,
transport='framed',
protocol='compact'
)
for i in hbase_cnxn.tables(): # 테이블 조회
table = hbase_cnxn.table(i) # 테이블 커넥션 생성
for k,r in table.scan(): # 테이블 모든 데이터 조회
print(table, k,r)
hbase_cnxn.create_table( # column family
tableName, {"cf2": dict()} # Use default options.
)
column_name = "{fam}:artist_name".format(fam="cf2")
# column 이름은 ${column family}:${column name}으로 구성됨.
for i, value in enumerate(greetings): #
row_key = "greeting{}".format(i)
table.put(row_key, {column_name.encode("utf-8"): value.encode("utf-8")})
for key, row in table.scan():
print(key,row)hbase는 auto increment가 없음.
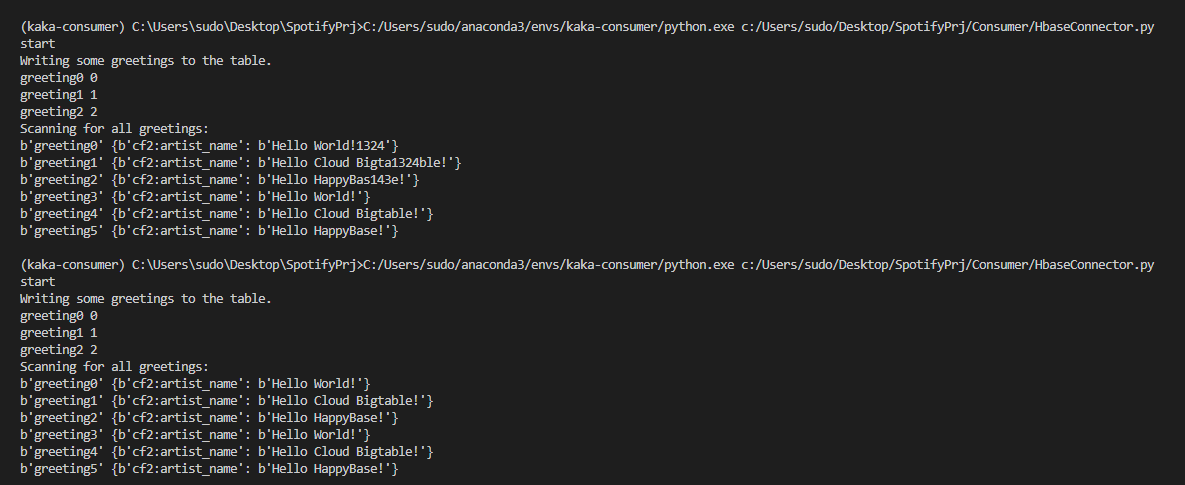
row data가 새로 쓰여지는 것을 볼 수 있음.
완성본
from kafka import KafkaConsumer
from json import loads
import time
import happybase
import uuid
class Consumer:
def __init__(self):
self.conn = happybase.Connection(
host='192.168.56.101', port=9090,
table_prefix_separator=b'_',
timeout=None,
autoconnect=True,
transport='framed',
protocol='compact'
)
self.consumer = KafkaConsumer("spotify",
bootstrap_servers=['127.0.0.1:9092'],
auto_offset_reset="earliest",
auto_commit_interval_ms=10,
enable_auto_commit=True,
group_id='kakao-group',
value_deserializer=lambda x: loads(x.decode('utf-8')),
consumer_timeout_ms=1000
)
self.tableName = "spotifytest"
self.table = self.conn.table(self.tableName)
self.batchSize = 1000
self.batch = self.table.batch(batch_size=self.batchSize)
def createTable(self, tableName):
try:
self.conn.create_table(
tableName, {"cf2": dict()}
)
print("success")
except:
print("exist table name")
pass
def getDataAtKafkaAndPutInHBase(self):
cnt =0
while True:
time.sleep(0.5)
print("sleep")
for message in self.consumer:
if cnt % 1000 ==0: print(cnt)
value=message.value
for data in value:
self.batch.put(str(uuid.uuid4()), {
"cf2:pos".encode("utf-8"): str(data["pos"]).encode("utf-8"),
"cf2:artist_name".encode("utf-8"): data["artist_name"].encode("utf-8"),
"cf2:track_uri".encode("utf-8"): data["track_uri"].encode("utf-8"),
"cf2:artist_uri".encode("utf-8"): data["artist_uri"].encode("utf-8"),
"cf2:track_name".encode("utf-8"): data["track_name"].encode("utf-8"),
"cf2:album_uri".encode("utf-8"): data["album_uri"].encode("utf-8"),
"cf2:duration_ms".encode("utf-8"): str(data["duration_ms"]).encode("utf-8"),
"cf2:album_name".encode("utf-8"): data["album_name"].encode("utf-8")
})
cnt +=1
self.batch.send()
self.consumer.commit()
consum = Consumer()
consum.getDataAtKafkaAndPutInHBase()글쓴이는 auto increment를 uuid로 해결하였음.
https://cyberx.tistory.com/164
HBase 개념 정리
HBASE 란?1.1 HBase 소개Hadoop의 HDFS위에 만들어진 분산 컬럼 기반의 데이터베이스 입니다.구조화된 대용량의 데이터에 빠른 임의접근을 제공하는 구글의 빅 테이블과 비슷한 데이터 모델을 가지며,
cyberx.tistory.com
'데이터베이스' 카테고리의 다른 글
| MySQL Buffer Pool (0) | 2023.01.13 |
|---|---|
| MySQL redo, WAL (0) | 2023.01.12 |
| 오랜만에 하둡 설치기(2) - 주키퍼를 설치하고 HBASE를 얹어보자 (1) | 2022.12.30 |
| redo, undo (0) | 2022.12.29 |
| 비관적 락 종류 간단 정리 (0) | 2022.12.20 |

