6. MySQL Operator의 동작 원리
- MySQL Opeartor이란?
사용자 정의 리소스를 사용하여 애플리케이션 및 해당 컴포넌트를 관리하는 쿠버네티스의 소프트웨어 확장판.
오퍼레이트는 쿠버네티스의 컨트롤 루프를 따름.
- 커스텀 리소스를 사용하여 쿠버네티스 오브젝트를 관리하는 이유
DB, 모니터링 시스템 등 오브젝트들이 복잡하게 엮여있는 워크로드에서 사용자가 직접 오브젝트를 관리하기 쉽지 않다.
그렇기 때문에 CDR을 사용해 추상화하여 관리를 쉽게 맏늠.
- 그렇다면 MySQL Operator는 어떡게 추상화하여 관리할까?
--------------------------------------------------------------------------------------------------
The MySQL Operator for Kubernetes is an operator focused on managing one or more MySQL InnoDB Clusters consisting of a group of MySQL Servers and MySQL Routers. The MySQL Operator itself runs in a Kubernetes cluster and is controlled by a Kubernetes Deployment to ensure that the MySQL Operator remains available and running.
--------------------------------------------------------------------------------------------------
공식 DOCS 기준 다음과 같은 문장이 존재함
- InnodbCluster를 관리해잠. InnodbCluster이란 Router 및 MySQL server로 이루어짐
- 쿠버네티스 클러스터에서 동작하며 오퍼레이터를 Deployment로 배포하여 제어함.
다음은 MySQL Operator의 아키텍처임.
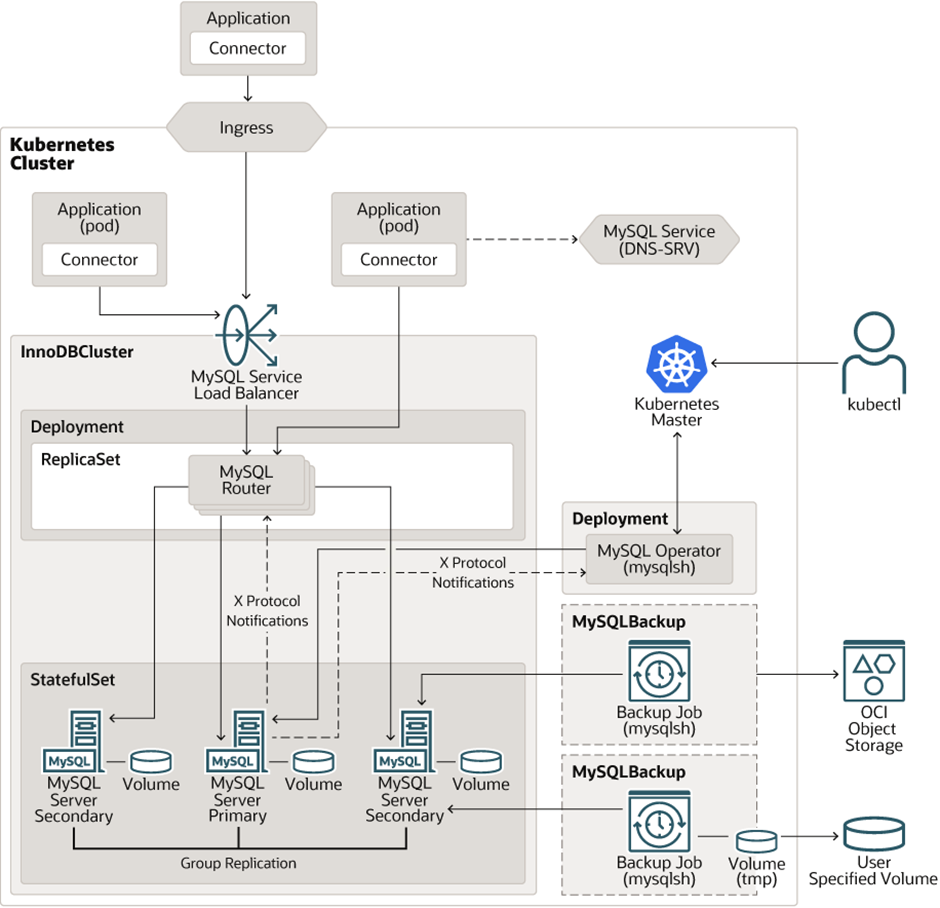
주요 구성 요소는
- Router
MySQL 서버들 중 작업을 실행할 서버를 선택하는 statless한 애플리케이션임.
DB인스턴스를 캐싱하여 라우팅할 인스턴스를 관리함.
Replicas를 조절하여 수평적 확장이 가능함
- MySQL Server Instances
MySQL 서버에서 실제 DB역할을 하게 됨. 클러스터 복제 방식은 Master-slave, Master-Master 방식 중 하나를 선택함.
—
복제 방식
1. Master 서버로 요청이 들어옴.
2. SQL thread는 해당 요청을 실행하고, bin log에 기록함.
3. Master thread를 이용해 slave(혹은 마스터)의 i/o thread에 전송함.
4. slave의 i/o thread는 relay queue에 쿼리를 넣음.
5. slave의 SQL thread가 해당 쿼리를 실행함

3. MySQL Operator
위의 MySQL 서버, Router를 관리함.
InnodbCluster, MysqlBackup 등의 사용자 정의 리소스를 통해 각 리소스의 배포를
자동화함.
MySQL은 다들 어떡게 동작하는지 알 것이다.
그럼 다소 생소한 Router는 어떡게 동작할까?
- 애플리케이션과 InnodbCluster 클러스터 간의 투명한 라우팅을 제공하는 경량 미들웨어 프로그램
- 클라이언트나 애플리케이션에서 수행한 쿼리를 MySQL 인스턴스로 전달하는 프록시 역할을 수행함.
다음과 같은 역할을 수행할 수 있음.
- 쿼리에 대한 로드 밸런싱
- Failover
- 클러스터의 구성 변경 감지

그럼 가장 중요한 클러스터에 대한 변경 감지를 어떡게 수행할까?
위에서는 클러스터의 정보를 캐싱하여 관리한다고 적었다.
그렇다면 그 과정을 알아보자.
- 클러스터 중 하나의 서버에 대해 오픈 커넥션을 유지함.
- MySQL의 performance schema에 쿼리를 수행하여 메타데이터 데이터베이스 및 라이브 상태 정보를 확인함.
– 클러스터의 메타데이터는 서버의 구성을 변경되거나, 테이블이 변경되면 업데이트됨.
– 라우터에 연괼된 MySQL 서버가 종료되었음을 감지하면, 다른 MySQL 서버에 연결하여 새 MySQL 서버에 연결하여 메타데이터 및 클러스터의 상태를 가져오려고 시도함.
InnodbCluster의 Failover
- Primary 인스턴스에 예상치 못한 실패가 발생하는 경우 자동적으로 새로운 Primary 인스턴스 선출을 위한 election이 진행됨.
- Secondary 서버 중 하나가 새로운 Primary 로 선택되어 동작하게 됨.
- 이 동작원리는 보면 모든 노드는 기본으로 읽기 쓰기 권한이 모두 가지고 있는데, 클러스터 정책에 의하여 하나의 노드 혹은 다중 노드로 Primary를 구성하여 읽기, 쓰기에 대한 정책을 설정하는듯 보임.
- // 뇌피셜이므로 정확한건 독스 가서 찾아보삼. 찾아보고 저도 좀 알려주셈
Router의 R/W 및 부하분산
일단 라운드 로빈 기반의 로드밸런싱을 기본으로 함.
- 먼저 클러스터 각 인스턴스 서버는 개별적으로 트랜잭션이 가능함. 다중 Master 노드
- 하지만 쓰기 트랜잭션의 commit 문제는 별개임. << 그룹에서 승인이 이루어져야 함
- 읽기 트랜잭션은 승인이 필요없고 commit됨.
- 쓰기 트랜잭션이 이루어지면 쓰기 트랜잭션은 모든 노드들한테 브로드캐스트됨.
- 만약 브로드캐스트된 트랜잭션을 수신한 서버의 수가 과반수 이상이라면 트랜잭션이 적용되고 해당 트랜잭션에 대해서 인증 처리하고 커밋을 진행함. // 해당 로직의 자세한 사항은 모르겠음….
자세한 내용은 아래 블로그를 참고
참고
- https://hoing.io/archives/5002
- https://hoing.io/archives/5003
- https://hoing.io/archives/5004
- https://yelimkim98.tistory.com/52
7. Redis 정리 – 보류
- 아 이건 진짜 못해먹겠다.
- mysql보다 더 복잡한듯
- 안해 ㅅ리;ㄴㅇ멀퍄ㅐㅕ레매프냐여
참고
8. 데이터 플랫폼 파트 트러블 슈팅
- ES의 Split brain
오류 메시지
—
CoordinationStateRejectedException: join validation on cluster state with a different cluster uuid FVufId5DQyGtGkhk9vy0Kg than local cluster uuid LAnJchLNRQuBxGo8rrpXCw, rejecting
—
기존에는 2개의 마스터 노드와 2개의 데이터 노드, 1개의 코디네이터 노드로 구성하였다.
위 오류 메시지를 해석하면, 기존 uuid a를 가진 클러스터에 uuid b라는 클러스터가 참여하려고 했을 때, 거절했다는 내용이다.
이러한 문제점이 발생한 이유는 클러스터는 투표 시스템을 활용하여 마스터(Primary)를 선출한다. 근데 네트워크 장애로 인한 master 단절 시 각 마스터 노드는 자신에게 투표하여 클러스터를 구성한다.
서로 달라진 uuid로 인해 클러스터 구성이 안됐다는 내용이다.
이것을 해결하려면 투표 권한을 가진 마스터 후보 노드를 3개 이상의 홀수로 구성하는 것을 권장한다.
- 카프카 커밋 오류
카프카 컨수머를 이용하여 브로커 서버에서 pull하여 레코드를 당겨오는 중, 데이터 중복이 발생하였다. 이유는 auto커밋의 동작 안하면서 생긴 오류이다.
오토 커밋은 일정한 주기를 가지고 커밋한다. 하지만 마지막 레코드를 가져오고 다음 레코드가 없어서 오토 커밋이 발생하지 않아 데이터 중복이 발생하였다.
위와 같은 오류를 수동 커밋으로 커밋 타입을 바꿔주면서 해결하였다.
- ES 인덱스 크기 관리 ( 오류는 아니지만 궁금해서 찾아봄 )
ES는 루씬 기반의 검색 엔진이다. ES는 문서 버전으로 데이터를 관리한다.
데이터가 변경되면 바로 삭제되지 않고 세그먼트가 달라지면서 COMMIT POINTER가 새로운 세그먼트를 가르키게 되면서 delete docs의 크기가 늘어난다 ( 세그먼트의 개수가 늘어남 ). 여기서 문서의 업데이트가 계속 일어나면 인덱스의 크기가 계속 커질것이라 생각하고 해당 문제점을 어떡게하면 처리할 수 있을까? 라는 고민을 하게 되었다.
ES는 merge policy라는 정책이 존재한다. 해당 정책을 통해 일정한 크기 혹은 세그먼트의 수를 기반으로한 merge를 진행하면서 segment의 크기를 관리한다.
기본 값은 5GB를 도달하면 merge가 일어나게 되고, force merge를 통하여 세그먼트를 합치는 방법도 존재한다.
아이작 피셜로 건드리지 않고 그냥 냅둔다 말씀하셔서 적용하려다 말았다.
'MySQL' 카테고리의 다른 글
| MySQL Operator (0) | 2022.11.30 |
|---|
