티스토리가 터져서 여기다 씀
멀티노드 카프카 클러스터란?
분산 시스템으로서 카프카의 성능가 가용성을 함께 향상 시킬 수 있도록 브로커 서버를 배치하는 것
스케일 아웃 기반으로 노드 증설을 통해 카프카의 메시지 전송과 읽기 성능을 (거의 // 클러스터끼리 네트워크 i/o 덕분에 선형적이지는 않음.) 향상시킴.
데이터 복제를 통해 분산 시스템 기반에서 고가용성을 지원한다.
분산 시스템에서 고려해야할 요소는
1. 성능
2. 안정성
3. 가용성
분산 시스템은 대량의 데이터를 여러 노드 간 분산 처리를 통해 빠르게 처리할 수 있는 큰 성능적 이점을 가지지만 안전성과 가용성에서는 단점도 있음.
- 네트워크 장애가 발생 시, 노드간 통신이 안되어 복제, 분산 처리가 가능하지 않음.
하지만 단일 노드에서 브로커 서버를 증설한다면 위의 단점은 없앨 수 있지만, 해당 노드가 죽으면 처리가 불가능하므로 단점도 존재한다.
- 운영해야할 요소를 잘 고려해서 사용해야함.
카프카의 구성
--------------------------------------------------------------------------------------------------------------------------------------------
카프카에서 사용하는 프로토콜??
바이너리 프로토콜!
인터넷에서 주로 사용하는 HTTP, SMTP, FTP >> 텍스트 프로토콜
>> 디버깅 등 관리는 쉽지만 바이너리 프로토콜보다 느림.
바이너리 프로토콜은 TCP, UDP 등과 같은 바이트를 사용하는 프로토콜임.
>> 사용자가 직접 이해하기는 힘들지만, 컴퓨터 입장에서는 인코딩/디코딩이 필요없어 빠른 속도를 보여줌.
카프카는 바이너리 프로토콜을 이용하기 위해 모든 API에 대한 요청과 응답 메시지의 바이트 구성을 정의함
--------------------------------------------------------------------------------------------------------------------------------------------
카프카는 브로커서버에 대한 "하나"의 커넥션을 유지하므로, TCP 핸드셰이킹이 한번만 일어난다.
클라이언트는 브로커 서버와 하나의 소켓 연결은 구성한다. 그 연결을 통해 요청 메시지를 쓰고 응답 메시지를 읽는다.
이렇게 된 소켓 덕분에, 개별 TCP 통신에 대해서 TCP 핸드셰이킹를 생략할 수 있다.
--------------------------------------------------------------------------------------------------------------------------------------------
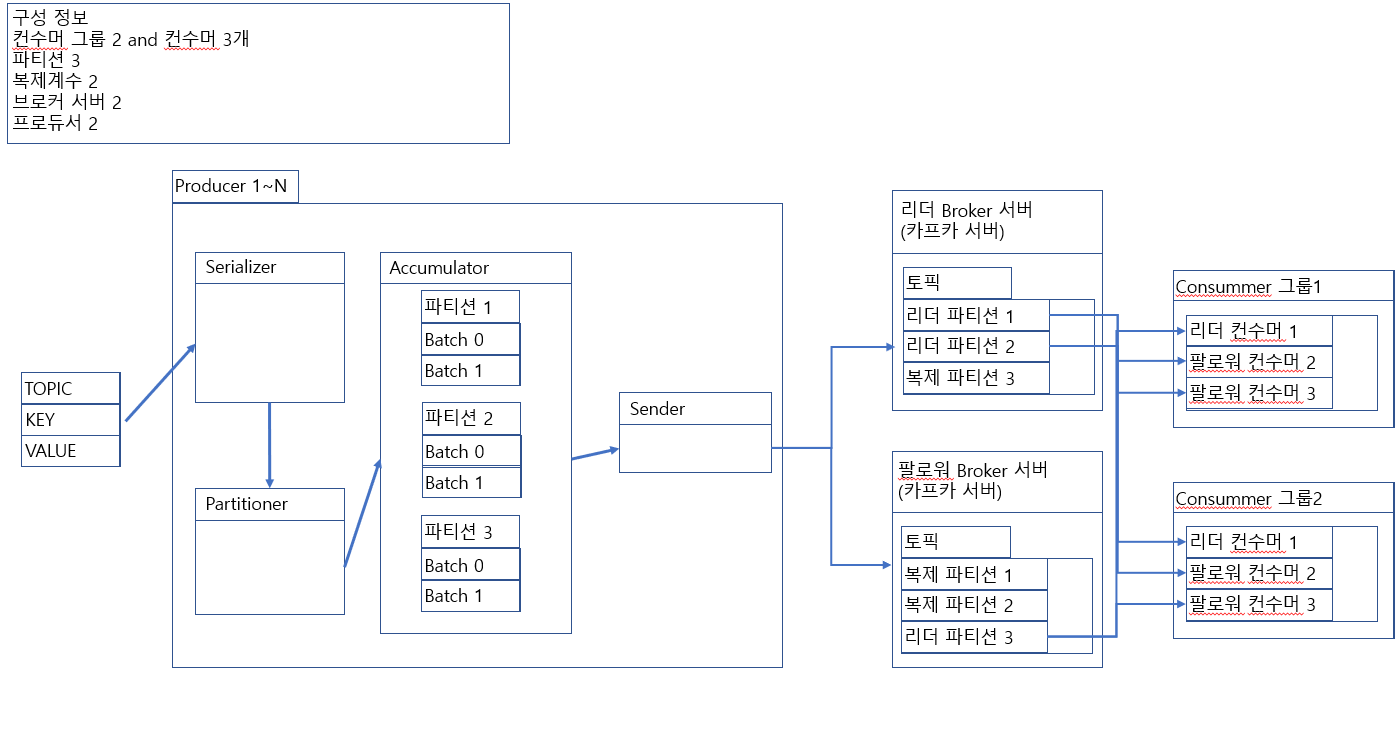
프로듀서
- sender : Accumulator에 일정 시간 및 일정 크기가 넘어서면 별도의 쓰레드를 할당받은 sender에 의해 해당 브로커 서버로 전송됨
- serializer : 프로그램에 의해 들어온 데이터를 바이트화
- partitioner : 레코드를 파티션에 할당 및 accumlator에 적재
- accumulator : 하나씩 브로커 서버로 전송하게 되면 네트워크 자원을 너무 많이 사용하므로 부담이감. 그래서 일정 배치사이즈로 나누어서 전송하게됨. 배치사이즈 이상이 되면, 다른 객체에 배치사이즈 만큼 레코더를 축적하게됨.
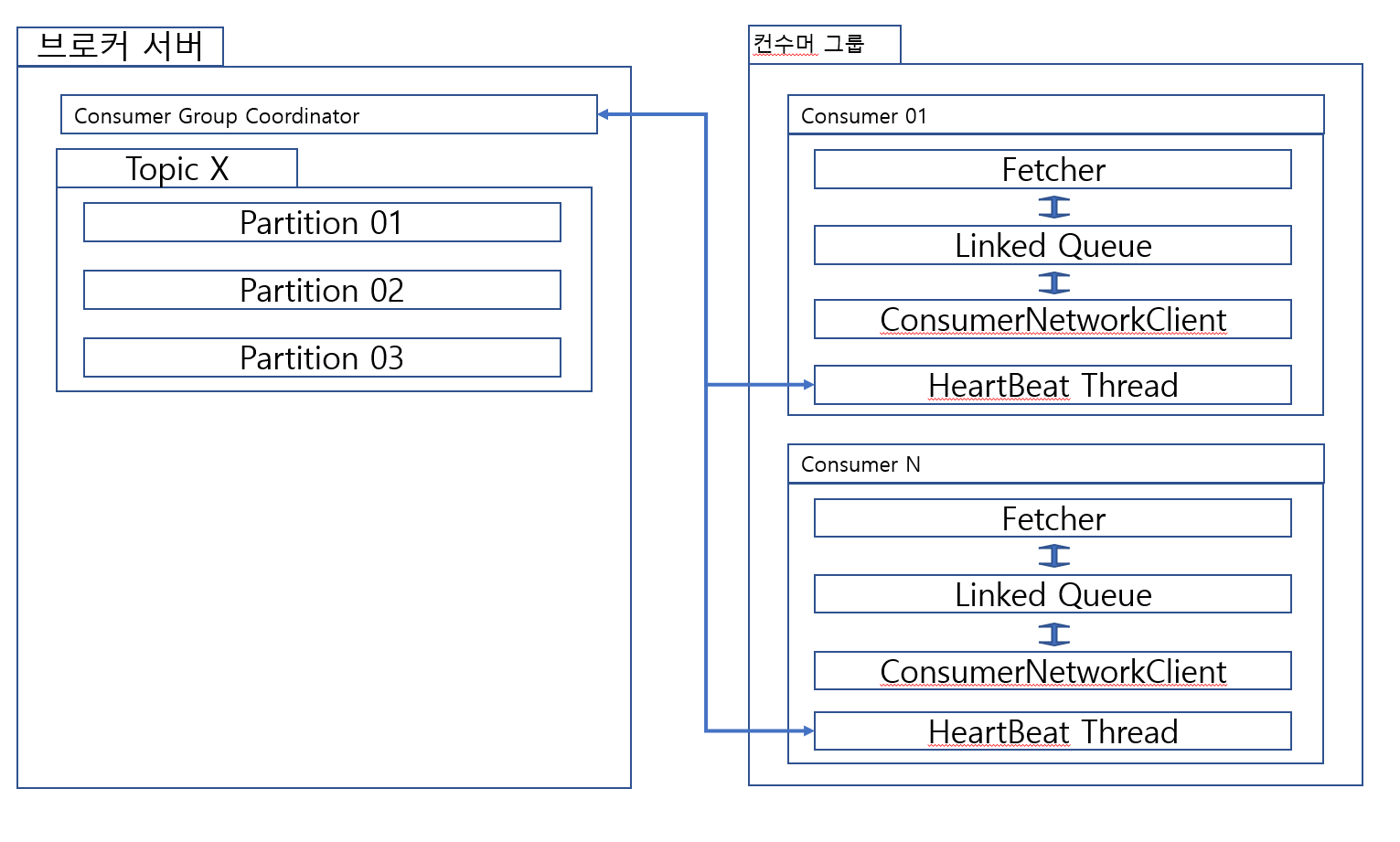
컨수머
- Fetcher : Queue에 존재하는 데이터를 가져오고 알림.
- Linked Queue : 그냥 Queue
- ConsumerNetworkClient : 토픽에 존재하는 데이터를 가져와 Queue에 삽입
- Heart Beat Thread : 자신이 살아있다고 컨수머 코디네이터에게 알림.
- ( 이건 브로커 서버에 존재함 ) 컨수머 그룹 코디네이터 : 컨수머 그룹의 변화, 새로운 파티션의 추가 혹은 변경이 일어나는 것을 관찰하고 리밸런싱을 수행함.
컨수머 그룹 코디네이터
그룹 코디네이터가 일정 기간(session.timeout.ms) 동안 컨슈머의 하트비트를 받지 못하면, 해당 컨수머는 어떠한 이유(장애, 종료 등)로 작업이 불가한 것으로 판단하고 해당 컨수머의 파티션 소유권을 다른 컨수머로 이관시킴.
컨수머의 Heartbeat, polling, commit 등 메시지를 여기로 전달하여 관리함.
컨수머의 리밸런싱
파티션 3개, 컨수머 그룹에 컨수머가 2개가 있다고 가정하자.
그러면 파티션이 2개,1개로 나누어서 컨수머에 할당될 것이다.
여기서 컨수머를 하나 늘리면 파티션 3개, 컨수머 3개가 되므로 컨수머 하나에 파티션 하나씩 할당되는 과정을 리밸런싱이라고 한다.
과정
1. 그룹 코디네이터는 컨슈머 그룹 내의 모든 컨슈머들의 파티션 소유권을 박탈한 뒤, 컨슈머들의 JoinGroup 요청을 일정 시간 기다립니다.
2. 그룹 코디네이터는 제일 먼저 JoinGroup을 요청한 컨슈머를 그룹 리더로 지정하고 그룹 리더에게 파티션 정도와 컨슈머 목록을 전달합니다.
3. 그룹 리더는 전달받은 정보를 바탕으로 파티션 소유권을 재조정하고, 이를 그룹 코디네이터에게 다시 전달합니다.
4. 그룹 코디네이터는 재조정된 파티션 소유권을 각 컨슈머에게 알리고 리밸런싱을 종료합니다.
이거 자주 일어나면 서비스 지속못함.
리밸런싱이 일어나는 과정에서는 데이터를 받아오지 못하기 때문.
그래서 스태틱 그룹 맴버쉽이라는 기능을 사용함
토픽 파티션에 대한 이해.
고가용성을 유지하기 위해, 파티션을 복제하여 리더 파티션과 팔로워 파티션으로 나눠 존재한다.
파티션에는 ISR ( InSync-replicas ) 이 존재하는데, 리더 파티션이 팔로워 파티션에 복제를 해놓게 된다. 이때, 모든 복제가 정상적으로 완료되었으면 해당 팔로워 파티션은 ISR에 들어간다.
리더 파티션은 ISR을 모니터링을 수행하면서 관리하고, 팔로워 파티션이 복제하지 못하고 뒤쳐질 경우 ISR에서 제외된다.
여기서 ISR 인지 아닌지 판단하는 방법은 리더의 offset 정보와 팔로워의 offset 정보를 기반으로 얼마나 잘 수행하고 있는지 판단함.
여기서 최소한의 ISR을 유지하기 위한 옵션도 존재하며, 최소조건을 만족하지 않을 시에는 재전송을 한다.
카프카 컨트롤러란?
1. 카프카 클러스터에서 하나의 브로커가 컨트롤러(리더)역할을 수행함
2. 브로커의 상태 체크, 죽은 브로커가 담당한 파티션의 새 리더 선출 및 새롭게 선출된 파티션 리더의 메타정보를 모든 브로커에게 전달함.
- 카프카는 주키퍼에 메타정보를 저장하여 동작한다.
리더 선출( Election ) 과정
카프카 서버 ( 브로커 서버 )가 3개 있고, 토픽 하나에 파티션 3개, 복제 계수 3으로 설정했다고 가정하자.
=====================================
브로커 1 : 파티션 1 (리더), 파티션 2, 파티션 3
브로커 2 : 파티션 1, 파티션 2 (리더), 파티션 3
브로커 3 : 파티션 1, 파티션 2, 파티션 3 (리더)
=====================================
브로커 3이 죽었다고 생각하자.
그러면 브로커 3에 있는 파티션 리더가 Heartbeat를 컨수머 그룹 코디네이터로 보내지 않으면서 리밸런싱이 일어난다.
1. 주키퍼는 session 유지 기간 동안 heartbeat가 오지 않으므로 해당 브로커 노드 정보를 갱신한다.
2. 컨트롤러 ( 리더 브로커 서버 ) 는 주키퍼를 모니터링 하던 중 브로커 서버가 다운되었다는 정보를 받음.
3. 컨트롤러는 다운된 브로커가 관리하던 파티션들에 대해 새로운 리더,팔로워를 결정함.
4. 결정된 파티션의 리더,팔로워 정보를 주키퍼에 저장하고 해당 파티션을 복제하는 브로커들에게 새로운 리더,팔로워 정보를 전달하고 새로운 리더로부터 복제를 수행할 것을 요청함.
5. 컨트롤러는 모든 브로커가 가지는 메타데이터 캐시를 새로운 리더,팔로워 정보로 업데이트할 것을 요청함
문제점 ?
1. 좀비 컨트롤러 이슈.
카프카 페일오버 시 새로운 컨트롤러가 로딩되는 과정에서, 이전 컨트롤러가 살아있으면 문제가 됨.
해당 문제를 컨트롤러 버전을 만들어서 해결했다고 함.
2. 새로운 컨트롤러 선출 시, 클러스터의 메타 정보를 다시 브로커 서버들에게 전송해야하는데, 이때 성능저하 문제가 생겼다고 함.
- 작은 단위의 메타정보를 하나씩 보내면서 성능저하가 일어남.
- 이것도 한번에 보내게 로직을 변경하여 해결했다고함.
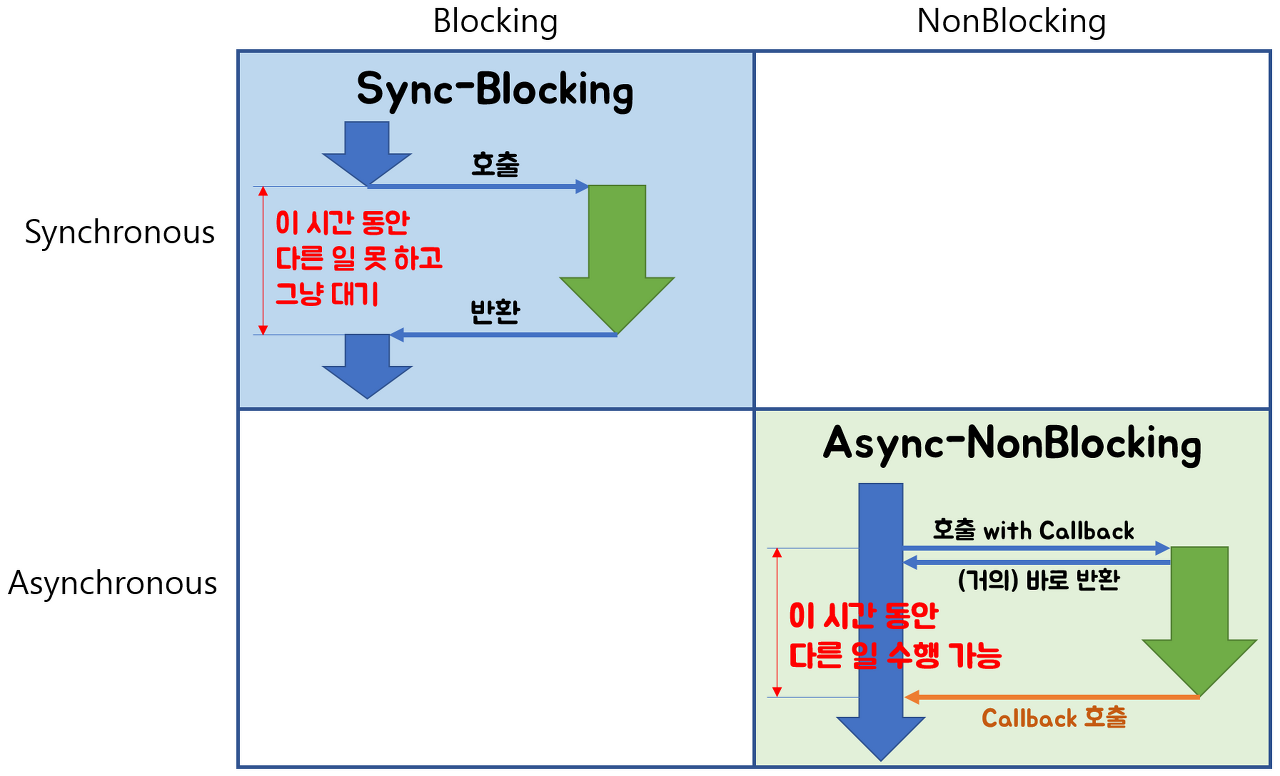
* 논블록, 블록 / 동기, 비동기
Blocking / Non-blocking 은 호출된 함수가 호출한 함수에게 제어권을 바로 주느냐 안주느냐,
Sync / Async 는 호출된 함수의 종료를 호출한 함수가 처리하느냐, 호출된 함수가 처리하느냐의 차이다.
참고
https://always-kimkim.tistory.com/m/entry/kafka101-consumer-rebalance
https://whiteman97.tistory.com/m/166
'KAFKA' 카테고리의 다른 글
| RabbitMQ 정리 (0) | 2023.03.03 |
|---|---|
| kafka kraft - 어려워서 나중에 따로 정리..뭔가 좀 쿠버네티스랑 비슷한듯 싶은데,, (0) | 2022.10.18 |
| 카프카 컨수머 구조 (0) | 2022.10.08 |
| 카프카에서 메시지를 보내면 일어나는 일 (0) | 2022.10.03 |
| 카프카 (0) | 2022.10.03 |



