자... 욜로.. 한 번 사는 인생 즐기고 간다가 아니라, you look only once이다. 작명센스가 진짜 좋은 것 같다.
영상인식에 관한 학교 과제, 현업 서비스에 잘 사용되고 있는 yolo를 정리해볼까 한다.
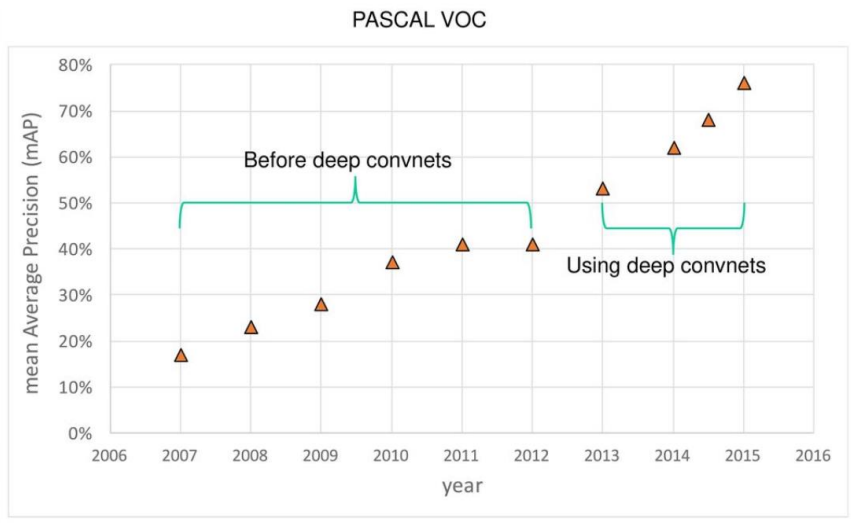
PASCAL VOC 데이터셋 기준 Object detection한 결과의 성능평가의 진화 과정이다. 딥러닝에 GPU를 도입함으로써 mAP가 급격히 올라가는 것을 볼 수 있다. 이제 내가 아는 선에서 간단히 sliding window, selective search, RPN 등 여러 개념을 살펴보겠다.
이미지 객체 탐지에는 여러가지 난제가 존재한다. 명확하지 않은 이미지, 데이터의 부족, 다양한 크기 및 모양의 객체, 영역 추정 등 다양한 문제가 존재한다. 이러한 문제들을 어떻게 해결하고 진화했는지 살펴보자.
0. 기본개념
0-1. conv layer
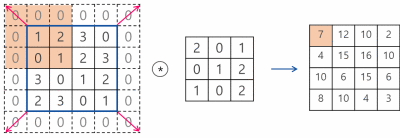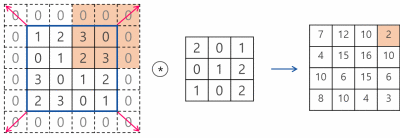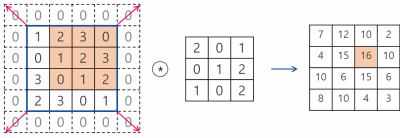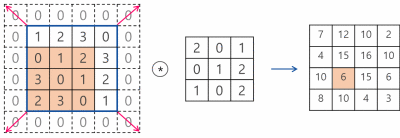
여기서는 3*3 필터를 사용해서 conv 연산을 수행했는데, 이 필터의 크기와 stride도 변경이 가능하다.
이 연산을 수행하고 나면, 이미지 혹은 2차원 데이터에 대한 특징이 함축적으로 추출된다.
0-2 fc-layer 및 dense layer
conv layer과 fooling layer를 반복적으로 거치고 flatten layer이 1차원 배열로 만들어주면, 해당 데이터에 대한 최종 특징들이 나오게 된다.
그러면 fc-layer이 해당 특징들이 어떤 object인지 판단해주는 object classification을 수행하게 된다.(여기서 activation function을 softmax를 취해줌으로써 object classification에 대한 각 확률을 구한다. 다중분류의 개념이라고 보면 됨.
이진분류에서는 sigmoid를 사용하는거랑 비슷함. 일반적인 hidden layer에서는 relu를 국룰로 사용함)
1. 영역 추정.
영역 추정 방식이란, object detection을 할 경우, 수 많은 bounding box의 수를 제한하기 위해 나온 개념이다.
이 개념을 도입함으로써 더욱 빠른 object detection 성능을 보여준다.
1-1. 1-stage detector, 2-stage detector


차이.
1. 속도는 1-Stage detector이 더 높음.
2. 정확도는 2-Stage detector이 더 높음. rpn의 경우 bounding box regression과 classification이 나뉨.
언제나 그랬듯이 좋은 성능이 주어지면 일반적으로는 속도가 떨어지는게 당연한 이치이다.
딥러닝만 해당되는 것이 아니라, DB, Networking, 보안, 다양한 오픈소스 등 다양한 분야가 모두 해당된다.
물론 획기적인 알고리즘이 나와서 속도만 올라가는 경우도 존재한다.
1-2. sliding window
초기의 object detection 방식은 sliding window 방식으로 진행했다.

image가 존재하고, 사각형 네모 박스가 이동하면서 객체를 탐지하는 문제이다. 이 경우에는 크기가 너무 작거나, 크기가 너무 크면 객체를 탐지하지 못하는 문제가 존재하였다. 그래서 이미지의 크기를 다양하게 변화시켜 객체는 탐지했다.

이 sliding window 방식은 수행 시간도 오래걸리고 검출 성능도 상대적으로 낮았다.
이 방식은 영역 추정 기법의 등장으로 활용도는 떨어졌지만, object detection 발전을 위한 기술적 토대를 제공했다고 한다.
1-2. selective search
이제 영역 추정 기법이 등장하였다. Selective search 알고리즘이다. Region proposal 기법의 대표 방법이고 한동안 많이 사용되었다. CNN으로 유명한 R-CNN계열, SPP-NET 등 여러 알고리즘에서 영역 추정 방식으로 채택되어 널리 사용되었고, anchor box 기법의 등장으로 열기가 사그라들었다.
동작 과정을 살펴보겠다.

1. 이미지가 들어가고, 모든 부분을 segmentation을 진행하게 된다. 이때 segmentation하는 방식은 2004년 발표된 논문의 efficient graph-based image segmentation 방식을 적용했다고 한다.
2. 모든 개별 segment들을 color, size, shape에 따라 유사도가 비슷한 영역을 grouping한다. 이때 grouping하는 방식은 greedy 알고리즘을 사용한다.
1~2 과정을 반복하면서 영역 추정을 실시한다.
간단한 개념은 이렇게 되는데, 자세한 개념은 논문을 찾아보길 바란다.
http://www.huppelen.nl/publications/selectiveSearchDraft.pdf
하지만 이 selective search는 end-to-end 학습이 불가능하고, 실시간 적용에도 어려움이 있어 RPN이라는 개념이 도입되게 된다.
1-4. RPN (2-stage detector)

드디어 영역 추정 방식에 Deep-learning 방식을 적용하였다. selective search 알고리즘을 대체하기 위해 나온 개념이다.
Region proposal network의 약자이다. End-To-End 학습이 가능하며 GPU를 활용해 빠른 Inference가 가능하다.
Region proposal network를 살펴보기 전, Anchor box를 살펴보겠다.

RPN의 입력으로는 CNN을 한번 거치고 나온 Feature map이 입력으로 들어온다.
1. 이 Feature map을 conv 연산을 적용한다. >> 다시 1*1 conv연산의 input으로 들어감.
2. 위의 conv 연산 결과에 score를 정하기 위하여 1*1 conv 연산을 진행한다. // 여기서는 해당 anchor box에 검출할 object인지 아닌지만 판단. >> 어떤 object인지는 faster-rcnn에서 판단함. IOU값이 0.7이상인 값은 PG, 0.3미만인 값은 NG로 각각의 LOSS를 구하여 학습을 진행함.
2-1. bounding box의 결과를 얻기 위해 1*1 conv연산을 수행한다.
여기서 bounding box regression을 구현하기 위하여 위의 anchor box의 개념을 사용하였다.
// bounding box의 좌표를 학습.

RPN의 소스코드의 일부를 보면 보다 직관적으로 이해할 수 있다.
https://github.com/kjh1997/frcnn-from-scratch-with-keras.git
GitHub - kjh1997/frcnn-from-scratch-with-keras: Faster R-CNN from scratch written with Keras
:collision:Faster R-CNN from scratch written with Keras - GitHub - kjh1997/frcnn-from-scratch-with-keras: Faster R-CNN from scratch written with Keras
github.com
1-5. anchor box
anchor box는 다양한 모양, 크기를 포착하기 위해 위의 사진과 같은 여러 박스를 사용하였다.
한 anchor에 위의 사진과 같은 9개의 박스가 존재한다. 총 anchor의 개수는, 이미지크기가 600*800일 경우, sub-sampling ratio=1/16이다. 가로 세로가 각 600, 800이니, 가로 * sub-sampling-ratio * 세로 * sub-sampling-ratio가 된다.
anchor box는 이렇게 구성된다.


1-5 SPPNET ( 1-stage detector)
SPPNET은 CONV레이어가 고정된 크기의 입력을 취하는데 발생한 문제를 개선하기 위하여 고안됐습니다.
기존 CNN은 고정된 입력 크기를 맞추기 위하여 CROP, WRAP를 적용했는데, 이 경우에는 이미지가 뭉게지고 잘려나가고 다양한 문제점이 발생했다.
이 SPPNET에서는 이미지의 크기를 변경하여 고정된 크기의 입력을 취하는데 발생하는 문제점을 개선했습니다.
쉽게 말해서 오브젝트를 고정된 크기의 사이즈로 바꿀 때 발생하는 이미지가 뭉게지고, 잘리는 현상을 없애줬음.
그럼 왜 고정된 크기의 사이즈가 필요할까?
CNN은 CONV layer와 fc layer 2개의 part로 구성됨.
CONV layer는 고정된 입력 이미지가 필요없지만, fc layer의 경우 고정된 사이즈의 이미지가 필요하기 때문임.
tensorflow나 torch의 코드를 보면 이해가 확실히 가는데 github가서 찾아보면 알게됨.

그래서 위의 이미지처럼 CONV layer와 fc layer 사이에 SPPNET을 추가해서 고정된 input이 들어가게 해줬음.
1. 아래의 사진처럼 하나의 이미지를 처음에 정해준 영역으로 나눠줌. // 이걸 bin이라 부름
2. 고정된 길이의 vector로 변환.
3. fc layer를 활용하여 object classification

1-7 FPN(Feature Pyramid Network)

작은 object를 보다 더 검출하기 위해 나옴. 맨 위에 적어 놓은 Sliding window에서도 이런 비슷한 개념을 적용했다.
그거랑 비슷하다고 보면 되는데 연산 과정이 좀 다르다.
1-8 PAN(Path Aggregation Network)
Segmentation 모델에 제안된 모델인데, Yolo v4의 nect에 적용되었다. 그래서 간단히 살펴본다.

FPN을 기반으로 만들어졌다. 초기 값이 결과 예측 부분에 반영이 잘 안되어 PAN이라는 개념이 등장하였음
이름에서도 알 수 있듯이 경로 집계 네트워크, 처음의 FPN의 CONV 출력과 FC layer를 이어줌으로써 더욱
propagation이 잘 이루어지도록 만들었음. 이게 끝임 별거 없음. 자세한 연산과정은 찾아보기바람.
1-9 bof (bag of freebies), bos (bag of specials0
bof는 inference cost의 변화 없이 성능 향상할 수 있는 딥러닝 기법. 대표적으로 데이터 증강(CutMix, Mosaic 등)과 BBox(Bounding Box) Regression의 손실 함수(IOU loss, CIOU loss 등)
BOS는 BOF의 반대로 inference cost가 발생하지만 성능 향상이 되는 딥러닝 기법. 대표적으로 enhance receptive filed(SPP, ASPP,RFB), feature integration(skip-connection, hyper-column, Bi-FPN) 그리고 최적의 activation function(P-ReLU, ReLU, Mish 등)이 있습니다.
2. 딥러닝 모델의 용어 정리(?)
딥러닝 모델링의 경우 3가지 PART로 구분한다.
1. Backbone : ResNet, DenseNet, VGGnet 등 여러가지 백본이 존재한다. 정보통신기술용어 사전에 따르면, 근간이 되는 뼈대를 의미한다. 이 말은 곧 이미지가 들어왔을 경우 feature extractor의 역할을 수행하고 feature map이 생성된다.
2. Neck : Backbone과 Head를 연결하는 부분. feature map을 재구성 및 정제하는 역할을 수행하고 Head의 input으로 들어간다. 대표적인 예시로 YOLO의 구성요소 중 FPN, PAN이 해당된다.
3. Head : 들어온 입력에 대한 classification과 bounding box regression(bbox regression이라고도 불림)이 수행된다.
// 이건 2-Stage detector이고 1-Stage detector의 경우 classification과 bounding box regression이 통합되어있다.
3. YOLO
위에 나온 개념들을 하나씩 조합해보면 이해가 됨.
백본은 CSPDarknet53을 사용했으며, neck은 SPP + PAN을 사용했고, HEAD부분은 YOLOv3을 사용했다.
덤으로 bos, bof 기법이 추가적으로 들어감.

전체적인 구조는 이렇게 구성되어 있다.
v3랑 비슷하면서도 좀 다름. backbone도 변화했고, pan이라는 기법이 추가됐음.
참고.
1. 딥러닝에서 자꾸 채널(depth)이 줄어들고 늘어나는 것을 볼 수 있는데, 채널을 늘리는 것은
한 이미지가 있다고 가정하자. 이것은 채널이 하나인 이미지 일 것이다.
그럼 이 하나의 채널에 구조가 다른 3개의 필터를 적용하고 출력하게 되면 1개였던 채널이 3개였던 채널로 바뀐다.
하나의 이미지에서 많은 정보를 뽑아내기 위해 채널을 늘린다.
cnn필터의 경우 여러가지 형태가 존재하는데, 아래 사진에서 이해할 수 있다.

2. 채널을 줄이는 이유?
일단 채널을 줄이는 이유는 연산량을 줄이기 위함이다.

3. 채널을 줄이는 방법은 그냥 sum 연산을 수행한다. >> 궁금하면 코드를 보면 됨.
4. 데이터의 size를 줄이는 방법. pooling(max pooling, average pooling... 등)
overfitting, noise 제거의 역할을 수행함.
yolo공부하면서 faster-rcnn도 같이 공부를 했었는데, 어쩌다보니 같이 정리했습니다..
두서없이 정리한 것 같기도 하고... 이상입니다.