드디어 2022년도 중장기(?) 프로젝트가 시작되었다.
시작하기 전 작년에 했던 프로젝트를 간단히 정리하고 시작해야겠다.
작년에도 여러 프로젝트를 진행했었는데, 이번에는 감회가 좀 새롭다.
작년 이맘때만 해도 python을 막 시작하고 cs지식이 하나도 없었던 신생아와 같은 존재였는데,
1년간 한이음(방충재 추천 알고리즘 웹 서비스)과 충북대학교 Net&database lab에서 "이종 학술 검색 사이트 통합 기반 전문가 분석 고도화 및 가시화 기법 개발 연구" 프로젝트에서 beautiful soup, selenium을 이용한 크롤러를 개발하고,
유튜브, ntis, 울산항만 사이트 등 여러가지 사이트에서 데이터를 수집하면서 데이터 수집에 대한 이해와 naver, 공공데이터포털, scienceon api를 사용하면서 api를 활용한 데이터 수집에 대한 활용 능력을 길렀다.
또한 이러한 수집된 데이터를 가지고 LDA, Word2Vector, konlpy, nltk, gensim 등 다양한 자연어 처리 기술을 활용하여
수집 된 데이터들에 대한 주요 주제 및 키워드를 찾아 활용하므로써 자연어 처리에 대한 능력도 배양하였다.
embedding한 데이터로 딥러닝 모델도 돌려보았다.
또한 졸업작품으로 Hadoop ecosystem를 활용한 빅데이터 플랫폼을 개발하므로써, flume, kafka, storm, hive, ooize 등 다양한 오픈소스를 활용하므로써 오픈소스에 대한 거부감을 줄이고, 빅데이터를 처리하기위한 수집, 적재, 처리, 탐색에 대한 이해도를 높였다.
졸업작품/ 2021. 09. 01 ~ 2022. 11. 31
현재는 빅데이터 플랫폼에 대한 개발은 완료한 상태이고 플라스크로 머신러닝 서비스를 배포한 상태이다.
전문가 검색 프로젝트 / 2021. 08. 01 ~ 2022. 05. 31
전문가 검색 프로젝트는 동명이인을 구별하는 프로젝트이다. 중간보고까지는 rule기반 통합까지 진행하였고,
지금은 "name disambiguation in aminer: clustering, maintenance, and human in the loop"이 논문을 활용하여
딥러닝을 활용한 동명이인 통합을 진행하고 있다. 성능이 그렇게 좋지는 못하지만, 사용하는 모양이다.
이 논문을 요약해보자면,
충북대 김종훈, 충남대 김종훈, 서울대 김종훈 이 있다고 가정하자.
이 경우 rule 기반을 적용하면 쉽게 구분할 수 있다. 예를들면 학교가 다른 김종훈은 다른사람이다.
이를 응용하면 학과가 달라도 쉽게 구분할 수 있을 것이다. 하지만 학교와 학과가 둘 다 같으면??
연구분야로 결정할 수 밖에 없다. 하지만! 연구분야도 같다면..? 이러한 수 많은 경우가 존재할 것 이다.
이러한 이유로 있는 분야가 동명이인 구별에 관한 연구가 진행되고 있다.
이제 논문을 요약해서 설명해보겠다.
이 논문에서는 논문의 keyword, title, year, venue, 공동연구자의 이름, 소속을 feature로 두고 진행했다.
이러한 데이터들이 이제 준비가 되었다. 이 논문들은 한글 혹은 영어로 되어있다. 이 데이터로는 딥러닝을 진행할 수 없다. 딥러닝을 진행하려면 w와 b가 적용될 수 있는 vector형태로 변환되어야 한다. 그래서 w2v기법을 적용해 데이터들을 embedding해주었다. 이 데이터를 동명인의 관계를 adjacency로 나타내고 그대로 딥러닝 모델에 적용해도 좋다.
하지만 그러면 각 동명이인과 논문들의 유클리드 거리를 파악할 수 없다. 그래서 metrix learning의 일종인 triplet이라는 개념이 등장한다.


triplet 모델의 구조는 위와 같다. 요렇게 해서 각 논문의 feature의 weight를 조정해주는 모델의 학습이 진행된다.
이 모델을 거치고 나온 데이터로 바로 클러스터링을 진행하여 결과를 도출하여도 좋지만, 이 논문에서는 vgae를 적용한 결과가 더 좋게 나와서 variational graph auto-encoders(vgae) 딥러닝 모델을 추가하였다. vage모델을 기존 auto-encoder(ae) 모델에서 여러단계를 진화한 모델이다. ae는 기본적으로 데이터에 대한 feature를 추출하여 latent vector z를 잘 도출하는 것을 목표로하는 encoder학습 모델이다. 덤으로 decoder 파트가 추가되어 reconsturction을 진행한다.

위의 결과를 보면 ae과 vae보다 명확하게 선명도가 떨어진다. 이 이유는

vae는 평균과 분산 개념을 도입해 좀 더 효과적인 decoder를 학습하였다. 이에대한 증명은 아래 유튜브에 가보면
정리가 아주 잘 되어 있다.
https://www.youtube.com/watch?v=54hyK1J4wTc&t=1000s
이제 vae에서 vgae로 넘어갈 시간이다. 차이는 별로 없다.
기존 fully connected layer에서 그래프의 edge와 node를 학습하기위한 graph convolution layer로 교채하였다.
graph convolution layer란 기존 이미지인식 분야에서 주로 사용되는 convolution layer에서 따온 개념이다.
feature metrix가 존재하고 adjacency metrix를 multiply연산을 수행함으로서 각 노드의 연관관계를 학습할 수 있다.
마지막으로 VGAE를 활용해 reconstruction한 데이터로 Hierarchcical Clustering(Hierarchical cluster analysis, HCA)를 진행해서 마지막 결과를 도출했는데, 성능은 50%정도?로 좋지 않은 성능을 보여주었다.

이 논문 하나 이해하려고 3주는 걸린 것 같다. 내 인생 첫 논문인데 생각보다 좀 어려웠다.
특히 딥러닝 논문 구현할 때, 하나의 library 및 frame-work만 사용하는게 아니라, scipy, numpy, tensorflow-keras 등 여러가지를 사용하니 정신이 너무 없었다. 이 코드도 나중에 정리해야겠다.
현재 개발중인 상황은, https://github.com/kjh1997/netdb_nlp.git 에 있다.
뭐 그래봤자, 기존 논문에 대한 코드가 엄청 많이 변화한 것은 아니다. 단지.. 개념을 이해하기 어려웠고, 코드분석하기가 좀 힘들었다.
또 이 프로젝트에서 처음으로 python을 활용해서 분산처리를 경험해 보았다.
multiprocessing과 threading을 처음으로 해 봤을 때 그 쾌감을 아직도 잊을 수 없다. 속도차이가 그렇게 날지 누가 알았을까? python 처음 배울 때 for문 돌리면서 "아~~~ 그냥 속도가 조금 빨라지는가 보다.." 라고 생각을 했었는데, 그렇게 빨라지는 것보면, 알고리즘과 분산처리의 필요성을 뼈저리게 느꼈다.



cpu의 코어와 gpu의 코어의 각각의 성능은 cpu가 우세하다. 하지만 gpu는 코어의 수가 압도적으로 많으므로, 간단한 연산이 많은 작업에는 gpu가 우세하다.
또 처음 gpu를 사용했을 때, cpu와 gpu의 딥러닝에서의 속도차이를 느꼈고, 서버컴퓨터를 날려먹어서 리눅스에 대한 공부도 덤으로 했다. 진짜 전문가 검색 프로젝트에서는 많은 것을 배웠다. 처음으로 협업다운 협업을 해 보았고, git을 활용해 프로젝트를 진행했었다고 생각한다.
방충재 추천 알고리즘 수행계획서 / 2021. 04. 01 ~ 2021. 11. 31
성과는 좋지 못했지만, 이 프로젝트를 계기로 Django 백앤드와 aws 리눅스 서버, 부트스트랩을 활용한 html, css, java scripts를 실전 프로젝트에 사용해 보았다. 나름 소중한 경험이다.
이 프로젝트에서 처음 putty와 filezilla를 사용했고, git과 리눅스 서버를 처음으로 다뤘지 않았나 생각했다.
이 프로젝트 덕분에 코딩에 흥미가 붙어 공부를 하고 있다고 생각한다.
Django로 웹서버를 개발함으로써 기본적인 server-client 구조에 대한 개념을 이해했고, 다른 nodejs, flask 등 여러가지 프레임워크를 사용할 경우에도 거부감이 없었다. 구조는 거의 다 비슷하고 언어나 파일 위치가 좀 다를 뿐이지 기본적인 mvt, mvc 구조는 같으니까...
또 데이터 수집 기술인 scrapy와 selenium을 배웠는데, scrapy는 이 이후로 단 1번도 사용한 적이 없다.
그래도 web의 dom에 대해서 이해했으니 좋은 경험이었다. 덕분에 beautiful soup을 처음 사용했을 때 너무 쉬워서 프로젝트에 많은 기여도 했었다.
이제 올해 시작하는 프로젝트를 소개하겠다.
올해는 본격적으로 빅데이터와 관련된 프로젝트만 진행하려한다.
기존에 공부하였던 Hadoop은 사용하지 않고, ELK 스택이라는 빅데이터 플랫폼 구현 스택을 사용할 예정이다.


Elasticsearch, Logstash, Kibana의 앞 글자를 가져와서 이름을 지었다.
Elasticsearch는 모두 넷플릭스와 페이스북이 사용하는 검색엔진으로 알고 있는 경우가 많을 것이다.
하지만 Elasticsearch는 검색엔진을 제외하고도 빅데이터 플랫폼으로 자리잡고 있다.
이제 Elasticsearch의 구조와 기능을 알아보겠다.
일단 Elasticsearch는 분산처리 nosql기반 데이터베이스이다!

Elasticsearch는 rest api를 지원하며, rest api를 이용하여 삽입, 삭제, 검색 등 쿼리가 가능하다.

핵심 개념 추가.
왜 Elasticsearch인가?
지금이야 빅데이터 플랫폼으로 많이 사용하기도 하지만, 초기의 Elasticsearch 개발 목적은 '검색엔진'이다.
모두 rdb 사용하면서 인덱싱 작업을 하면 좀 더 빠른 성능이 나온다는걸 모두 알고 있을 것이다.
Elasticsearch는 모든 Document에 indexing 작업을 하므로, 모든 column을 찾는 대신, 인덱스를 이용하여
필요한 document가 어디에 존재하는지 빠르게 검색이 가능하다.

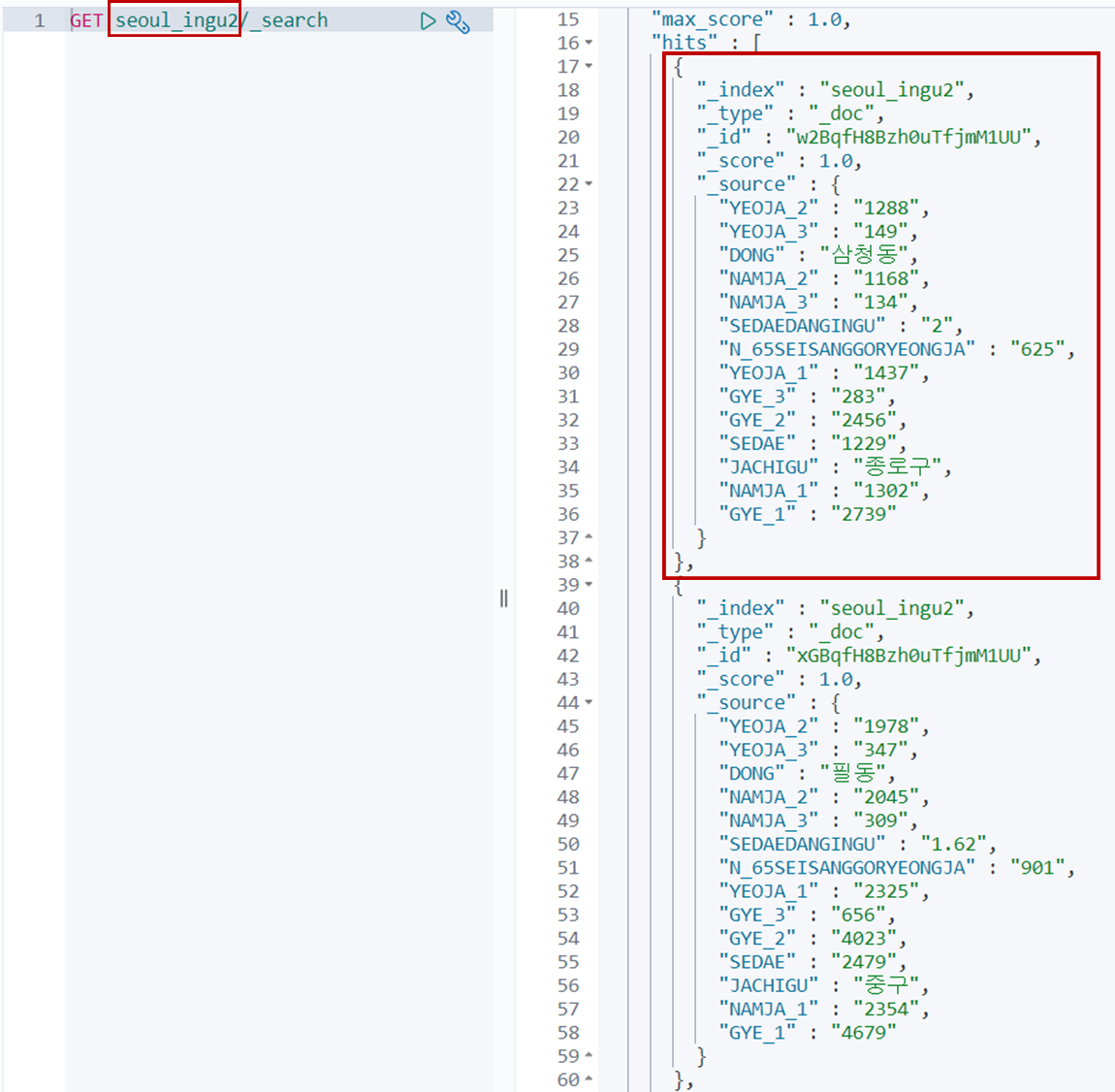
예전에 하던 예제에서 가져온 데이터인데, 오른쪽 빨간 네모가 하나의 Document라 한다.
또한 왼쪽의 쿼리에서 빨간 네모는 index이다.
json파일과 익숙한 사람들은 json파일 형식이라는 것을 눈치챌 수 있다.

클러스터 > 노드 > 인덱스(index/indices) > 샤드(shard) > DOM/Document
1. Cluster
하나 이상의 서버 혹은 노드가 모인 것. 이 클러스터를 통해 데이터를 분산 저장 및 분산 처리를 지원하며
클러스터에 대한 index 및 search 기능을 제공함.
Hadoop이란 비슷하지만 비슷하지 않은 오픈소스가 존재함.
2. Node
클러스터에 포함된 단인 서버. 데이터를 저장하고 indexing 및 search 기능에 참여함.
노드마다 각각의 역할이 다른 경우가 있는데, 예를들면 Hadoop에서의 master, data node. HBase에서의 master, region 등 여러가지 경우가 존재함. 이를 지원하기 위해 노드에 대한 이름을 구별해서 저장해야함.
Hadoop같은 경우는 주키퍼에 의존해 이 기능을 지원함.
3. Index
비슷한 특성을 모은 문서라고 할 수 있음. 고객, 제품 카탈로그, 주문 데이터 등 여러가지 index이 존재함.
4. Type
하나의 index에 하나 이상의 Type을 정의할 수 있음. Index를 구분하기 위해 존재하며, 사용자가 이를 정의함
5. Document
Document는 indexing 할 수 있는 기본 정보 단위.
6. Shard
Shard 방대한 양의 데이터가 저장 될 경우, 단일 노드에 모두 저장되면 과부하가 걸림.
그래서 샤딩이란 기능을 이용하는데, 샤딩이란 하나의 테이블(컬렉션)을 여러가지 조각으로 나눠 분산 저장하는 기술을 의미함.

7. Replica
데이터의 이중화. 백업, 미러링 등 다양한 방식으로 구현되는 복제를 의미함.
쿠버네티스, 하둡 등 다양한 오픈소스에서 이러한 개념을 이용함.(replica뿐만 아니라 다른 용어도 다 비슷하긴 함)
replica는 장애가 발생했을 경우 이를 대비(fail over)와 read cost 감소 등 다양한 이유로 사용되지만,
sharding은 데이터를 분산 저장함으로써, 트래픽의 분산에 목적이 있다.
비슷하다고 알고 있는 사람도 있는데, 명확히 하고 넘어가면 좋겠다.
이때까지 Mysql, Mongodb, Hbase, Redis, firebase 등 db, nosql db를 사용했는데, 내가 아직 수준이 높지 않아서 그런지, 각 db 특성마다 살짝 다를 뿐 필요한 기능은 다 있다고 생각한다. 다만 뭐가 더 익숙하고 익숙하지 않은지가 중요한 것 같다. 지금은 nosql이 좀 더 편한 것 같다. 나중에 graph db도 사용해 보고 싶은데 나중에 기회가 되면,,,,
아무튼! 이름이 좀 다르고 기본 사용방법은 다 같으니 적당히 docs를 검색해서 사용하도록 하자.

자 이제 Elasticsearch라는 데이터베이스가 존재한다. 그럼 데이터를 넣을 오픈소스 혹은 직접 만든 프로그램이 필요하다.
올해 프로젝트에서는 python elasticsearch를 이용하거나 logstash나 beat를 사용할 계획이다. 물론 이런 간단한 기능 말고도 flume, kafka, storm, spark 등 다른 하둡 생태계와도 연동이 가능하다. 하지만 여기서 그렇게 까지는 사용하지 않을 계획이다. 일단 기본적인 기능을 다 구현하고 프로젝트를 키우거나 할 생각이다.
이제 데이터베이스에 넣을 프로그램, 오픈소스가 준비되었다. 이제 실제 사용자 친화적으로 시각화해서 보여줘야한다.
ELK 스택 이름에서도 알 수 있듯이, 우리는 Kibana를 사용할 계획이다. Kibana는 데이터 탐색, 시각화, 분석하는 오픈소스이다.
"빅데이터와 공공데이터를 활용한 해상 재난안전 모니터링 및 예측 시스템"에서 내가 구현할 부분은 ELK 스택을 사용해서 다양한 API와 여러 웹사이드 DOM에 있는 데이터를 Parsing해서 시각화 하는 데이터의 수집, 적재, 처리, 탐색을 구현한다.
울산항만 인근 입출항 선박 인지 자동화를 통한 입출항 물류량 예측 시스템
올해 총 3가지 프로젝트 중 마지막 프로젝트이다.
위의 ELK스택을 그대로 가져다 사용할 예정이다. 하지만 라즈베리파이를 이용한 YOLO모델을 개발해야하는데, 이 분야는 좀 생소해서 내가 잘 할 수 있을지 모르겠지만, 내가 노력해서 못 이루는 결과는 아직 경험하지 못했다. 이 프로젝트 역시 노력하면 되지 않을까... 생각한다.
올해 작품 설계서


올해는 작년보다 더 좋은 성과를 거두는 한 해가 될 것 이다.
다음에는 ELK를 활용한 예제를 풀어보며 포스팅해야겠다.
너무 두서 없이 작성했는데 나중에 다시 정리해야겠다.
지난 1년간 많은 것을 배웠다고 생각한다. 이러한 기반을 토대로 이번 프로젝트에서 기여할 수 있는 기회가 되었으면 한다.
//
연구실에서 다양한 세미나를 진행했었다.
예를 들면
1. JAVA
2. algorithm
3. 쿠버네티스
이 정도 진행했었는데, 3가지 세미나 모두 도움이 됐었다고 생각한다.
이것도 취업하기 전에 정리를 해야될 것 같다.