빅데이터 취업을 위해 오랜만에 하둡을 다시 설치해 보았다.
환경
우분투 20.04
하둡 3.3.1
master : namenode
slave-1 : secondary namenode, datanode 1
slave-2 : datanode 2
sudo apt install -y net-tools ssh vim tree openjdk-8-jdk // 자주 사용하는것 설치
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
tar -xzf hadoop-3.3.1.tar.gz
vi .bashrc
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/home/hadoop/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
export HADOOP_STREAMING=$HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-3.3.1.jar
source ~/.bashrc
환경 변수 세팅 후 저장
/etc/hosts 설정
127.0.0.1 localhost
127.0.1.1 kjh-VirtualBox
192.168.56.101 master
192.168.56.102 slave-1
192.168.56.103 slave-2
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
============================================================================================
$HADOOP_HOME/etc/hadoop/yarn-site.xml 설정
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
# log 출력
<property>
<name>yarn.log-aggregation-enables</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
============================================================================================
$HADOOP_HOME/etc/hadoop/core-site.xml 설정
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
============================================================================================
$HADOOP_HOME/etc/hadoop/mapred-site.xml 설정
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>
============================================================================================
$HADOOP_HOME/etc/hadoop/hdfs-site.xml 설정
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:9870</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/kjh/hadoop-3.3.1/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/kjh/hadoop-3.3.1/data/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave-1:50090</value>
</property>
</configuration>
============================================================================================
$HADOOP_HOME/etc/hadoop/workers 설정
slave-1
slave-2
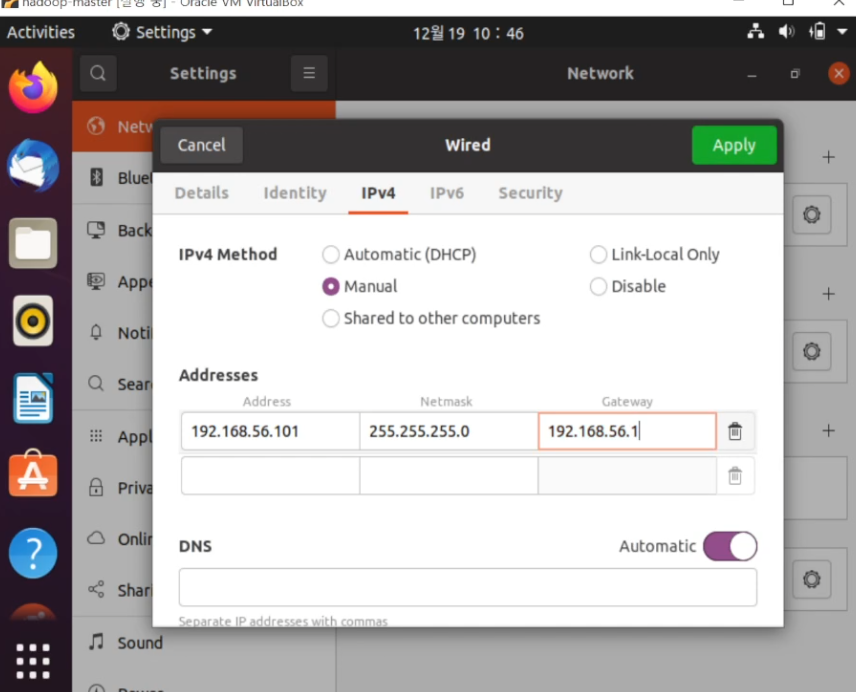
slave 복제 후 /etc/hosts 기반으로 ip 세팅
master에서만 실행
cd $HADOOP_HOME/sbin
하둡 실행
./start-all.sh
하둡 종료
./stop-all.sh
예제 준비
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/workspace
bin/hdfs dfs -mkdir /user/workspace/wordcount
bin/hdfs dfs -put etc/hadoop/*.xml /user/workspace/wordcount
예제 돌리기
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar grep /user/workspace/wordcount /user/worksapce/wordcount_result 'dfs[a-z.]+'
결과 확인
hdfs dfs -cat /user/worksapce/wordcount_result2/*
'데이터베이스' 카테고리의 다른 글
| redo, undo (0) | 2022.12.29 |
|---|---|
| 비관적 락 종류 간단 정리 (0) | 2022.12.20 |
| 데이터베이스 트랜잭션 격리 수준 (database transaction isolation) (0) | 2022.11.27 |
| 데이터베이스 인덱스, 디스크i/o (0) | 2022.11.11 |
| 데이터베이스 인덱싱하기 (0) | 2022.10.30 |