오늘은 한 2주전?에 엘라스틱서치가 빠른 이유를 알게 되었는데 그동안 바빠서 정리를 못했었다.
먼저 다들 알고 있을만한 역 인덱싱 또한 엘라스틱 서치가 검색에 빠른 이유 중 하나이다.
엘라스틱서치,,, 진짜 신기하다.
엘라스틱서치 = ES 라고 부르겠다. 타자치기 힘들고 말하기도 힘듬..
시작!
오늘 다루어볼 주제!
- ES는 트랜잭션과 롤백 개념이 존재하지 않는다.
- 업데이트라는 개념이 존재하지 않는다.
- 속도가 빠르다?? >> 완전 실시간 검색이 가능하지는 않음.
1. 트랜잭션이 없다?!?!
ES에서는 비용이큰 롤백, 트랜잭션을 지원하지 않는다.
그렇다면 ES에서는 쿼리를 어떡게 관리하고 충돌을 방지할까???
트랜잭션의 존재 이유는 ACID를 만족시키기 위해서이다.
트랜잭션은 개별적으로 이루어져야하며, 실행 전과 후가 똑같은 상태여야한다. 또한 각 트랜잭션끼리는 간섭이 불가능해야하며, 한번 실행된 트랜잭션은 반영구적으로 지속되어야한다. 라는게 ACID의 기본 정의라고 알고 있다.
이게 없으면 ES에서의 데이터는 엉망이 되는게 아닌가? 라는 의문을 가질 수 있다.
하지만 ES에서는 "낙천적 락"을 이용하여 충돌을 방지한다.
# 낙천적 락, 비관적 락에 대해서 찾아보시길
두개의 요청이 동시에 들어간다고 가정하자. 그럼 먼저 끝나는 요청이 반영되고, 나머지 하나의 요청은 해당 문서 버전이 이미 바뀌었기 때문에, 해당 쿼리를 다시 적용하거나 아예 적용되지 않는다.
위와 같은 특성을 지녔기 때문에 병렬적으로 연산이 가능하다.
ES의 검색 과정을 살펴보자.
요청은 코디네이터 노드를 거쳐서 마스터 노드로 전달되거나, 마스터 노드로 직접 전달될 것이다.
그러면 마스터 노드에 존재하는 search thread pool에 전달되게 된다.
해당 search thread pool에서 각각의 데이터 노드의 샤드에 쿼리를 날리게 된다.
데이터 노드들은 해당 요청을 받아 실행된다.
또한 ES 노드의 스레드 풀이란?
기본 값으로는 1코어당 1스레드 풀이다.
예) 32코어 > 32 스레드 풀 // 늘릴 수 있음.
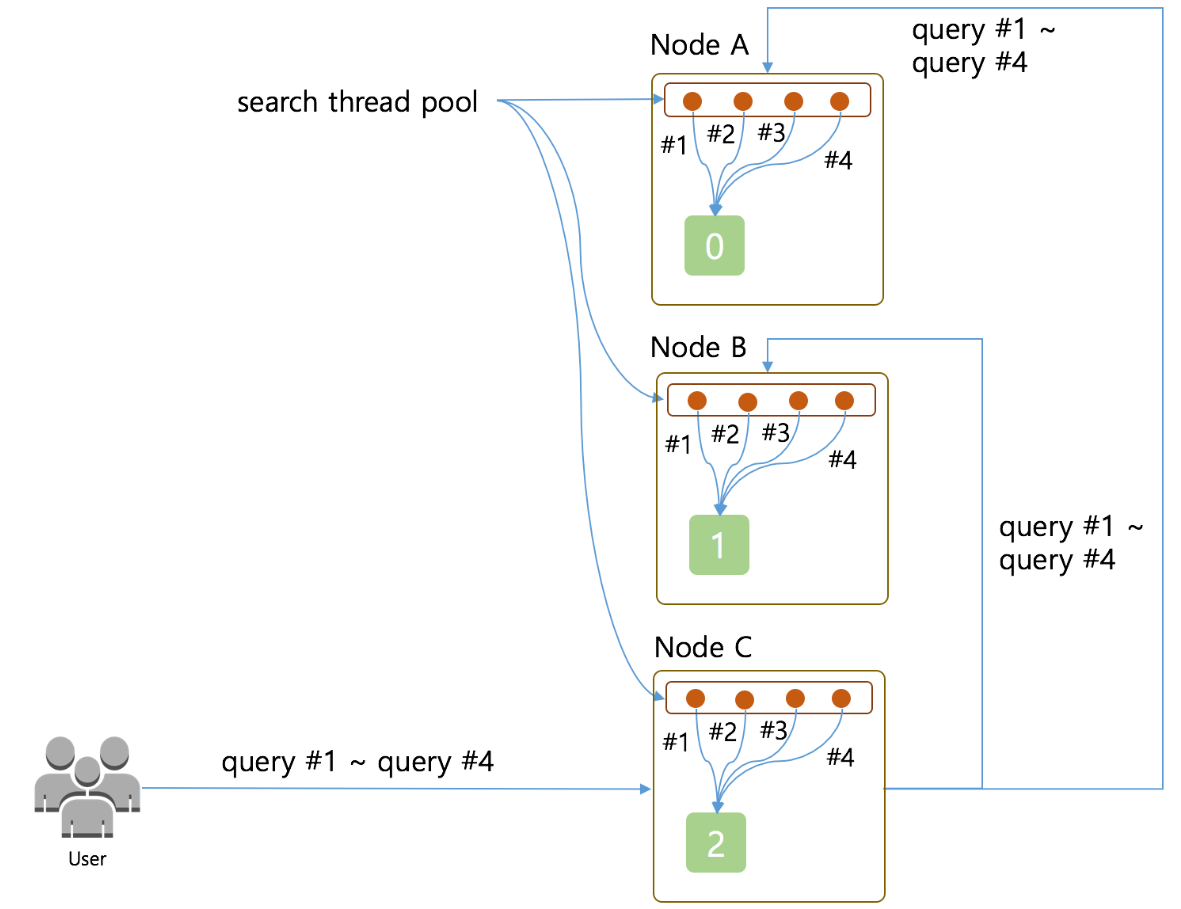
아래 사진은 퍼온건데, 각 노드에 마스터 + 데이터 롤이 들어갔다.
쿼리 실행 과정이다.

위 사진은 각 노드의 쓰레드 풀은 4개이고 단일 쿼리가 들어간 경우이다.
하나의 요청이므로 쓰레드는 1개만 사용되는 모습을 보여주고, 나머지 3개의 쓰레드는 접근할 샤드가 없으므로 놀고 있다.
그럼 샤드를 늘리면 스레드가 안놀겠지?
============================================================================================
무턱대고 늘리면 하나의 쿼리가 쓰레드 풀을 다 사용하여 효율적이지 못한 성능을 보인다.
단일 쿼리는 빠르게 끝나지만, 쿼리가 많이 요청되면 병목현상이 일어나게 된다.
큐가 꽉 차면 REJECT 현상이 발생될 수 있다고 한다.
============================================================================================
샤드가 너무 적으면?
각각의 쿼리마다 느린 성능을 보여준다.
그래서 자신의 클러스터에 맞는 샤드 최적화가 필요하다.
============================================================================================
2. 완전 실시간 검색이 불가능하다?
이건 쉽다.
데이터가 들어오면 다음과 같은 방식으로 디스크에 쓰이게 된다.
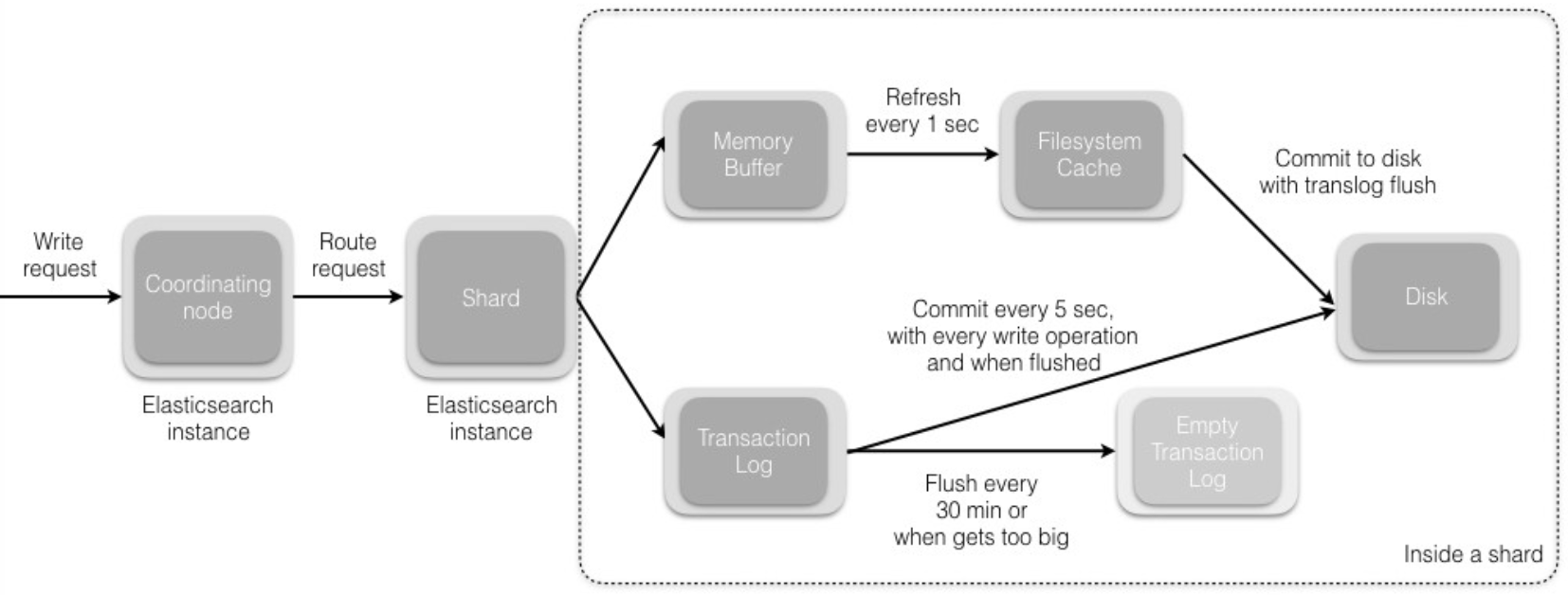
1. 데이터가 메모리 버퍼에 쌓이고 tranlog에 기록된다.
2. 메모리 버퍼에 쌓인 데이터들은 기본 값 1초마다 refresh되고 검색이 가능해진다.
- refresh된 데이터는 파일 시스템 캐시에 기록되고 tranlog flush 시점에 같이 디스크에 쓰이게된다.
- refresh 프로세스는 인메모리 버퍼의 내용으로 부터 새로운 인메모리 세그먼트를 생성한 다음 버퍼를 비우게 된다.
2-1 tranlog에 기록된 데이터는 30분마다 flush 되고 디스크에 기록된다.
https://foreversunyao.github.io/2018/01/databaseelasticsearch
Samuel's Blog | Elasticsearch
Lucene Apache LuceneTM is a high-performance, full-featured text search engine library written entirely in Java. It is a technology suitable for nearly any application that requires full-text search, especially cross-platform. Reverse_index: (°0°) (°0°
foreversunyao.github.io
https://kok202.tistory.com/121
Elasticsearch 활용 (성능 최적화)
하드웨어 관점 CPU 하이퍼 스레딩 포함 32코어 까지 대응. 32 코어 보다 크면 너무 많은 스레드가 생성되어 OOM 이 발생한다. CPU 사용률이 60% 이상이면 CPU 확장을 고려해보는 것이 좋다. RAM 최대 32 GB
kok202.tistory.com
https://brunch.co.kr/@alden/39
클러스터 설계하기 - #1 검색 성능과 샤드 개수
ElasticSearch | 이번 글에서는 ElasticSearch (이하 ES)의 클러스터를 설계하기 위해 필요한 요소들 중 샤드의 개수가 검색 성능에 미치는 영향을 바탕으로 적정한 샤드의 개수와 데이터 노드의 개수를
brunch.co.kr
'ES' 카테고리의 다른 글
| 엘라스틱서치의 루씬 검색 라이브러리 (0) | 2022.11.22 |
|---|---|
| elasticsearch (0) | 2022.10.27 |
