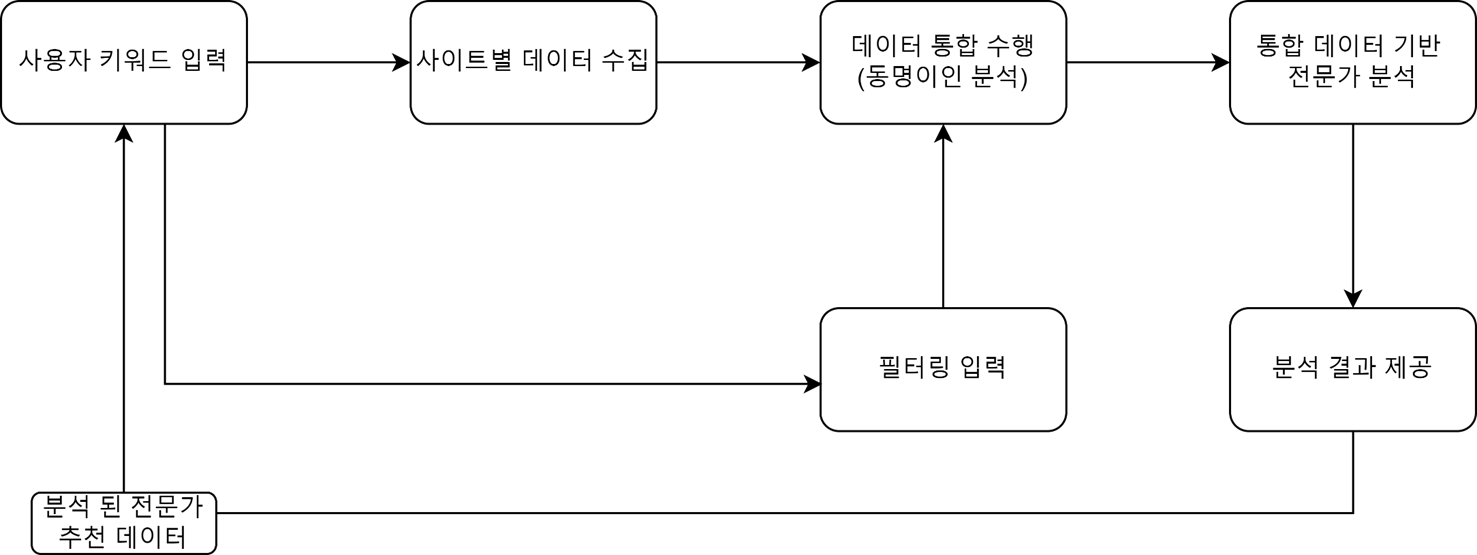
- 수집팀 : ntis, scienceon 포털을 api 및 selenium, beautiful soup을 활용하여 데이터 크롤링.
크롤링 되는 데이터에는 저자의 이름, 소속, rnd 정보, 연구과제 를 가져와서 mongodb에 적재
수집팀 기법들
1. TF-IDF
여러 문서로 이루어진 문서군이 있을 때 어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지를 나타내는 통계적 수치
2. LDA
문서의 집합으로부터 어떤 토픽이 존재하는지를 알아내기 위한 알고리즘
3. 코사인 유사도
내적공간의 두 벡터간 각도의 코사인값을 이용하여 측정된 벡터간의 유사한 정도
- 통합팀 : vgae모델을 사용한 동명이인 분석 및 hac를 활용한 클러스터링.
vgae 모델이란? Variational Graph Auto-Encoders
-- data의 분포를 학습하기 위한 GAE에서 변형된 방법이다. 오토인코더에 그래프 개념을 더하였음.
그래프 오토 인코더는 모델의 피처를 잘 표현하기 위한 잠재 벡터 z를 잘 표현하기위해 인코더부분을 주로 학습하지만,
vgae모델은 새로운 데이터를 더 잘 표현하기 위한 디코더 부분을 주로 학습시킴.
gae에서 디코더를 더 신경써서 학습한 것이 vgae
분산 그래프 오토인코더 모델. 오토인코더를 사용한이유?
논문에서는 vgae를 사용했을 경우 더 좋은 성능을 보여서 사용했다고함.

- 지수팀 : 수집팀에서 데이터를 수집 및 저장한 데이터를 바탕으로 지수를 구함.
지수는 협업도 품질, 생산성, 주제적합도임.
협업도는 얼마나 많은 연구과제를 수행하였느나,
품질은 얼마나 많은 인용수를 가졌느냐,
생산성은 최근에 얼마나 많은 논문 및 연구과제를 수행하였느나,
주제적합도는 우리가 검색한 키워드와 논문의 제목과의 코사인 유사도를 통해 구함.
많은 데이터를 처리하기 위해서는 속도가 중요함.
나는 빠른 속도로 데이터를 처리하기 위해 쓰레드단위의 멀티프로세싱을 진행하였음.
마지막에 다른 쓰레드들이 모두 끝나는것을 기다리고, 데이터를 한번에 몽고디비로 적재함.
하나씩 적재를 하게되면, 디비의 커넥션이 늘어남에 따라 느려질 수 밖에 없음